Overview
Qwen QwQ-32B is a 32-billion-parameter large language model released in March 2025 by Alibaba Cloud’s Qwen team huggingface.co venturebeat.com.It is part of the open-source Qwen (通义千问) series of LLMs built by Alibaba, which includes models of various sizes (from billions up to 70B+ parameters) for both base and chat purposes github.com. QwQ-32B was developed to push the reasoning capabilities of LLMs – its name “QwQ” denotes a specialized reasoning variant of the Qwen models, focused on complex problem-solving. The model integrates advanced reinforcement learning (RL) techniques into its training, allowing it to “think” through problems in a structured way beyond what conventional instruction-tuned models achieve huggingface.co. The primary goal of QwQ-32B is to achieve state-of-the-art reasoning performance (in areas like math and coding) comparable to much larger models, while being more computationally efficient qwenlm.github.io. By open-sourcing QwQ-32B under an Apache 2.0 license, Alibaba aims to provide researchers and enterprises a powerful yet accessible AI engine for complex tasks, free to use and customize in their own applications venturebeat.com. In summary, Qwen QwQ-32B represents a significant milestone in large language models – an open, mid-sized LLM purpose-built for high-level reasoning, introduced to bridge the gap toward more general AI problem-solving capabilities.
Technical Specifications
Architecture & Size: QwQ-32B is a decoder-only Transformer model with 32.5 billion parameters (about 31.0B non-embedding) huggingface.co. It uses a deep 64-layer Transformer stack with modern enhancements: Rotary positional embeddings (RoPE) for encoding long sequences, SwiGLU activation in feed-forward layers, and RMSNorm normalization – along with a slight QKV bias term in attention for improved training stability huggingface.co venturebeat.com. The model employs Generalized Query Attention (GQA) to optimize memory usage, dividing the attention heads into 40 query heads and 8 key-value heads huggingface.co venturebeat.com. These architectural choices are similar to other recent LLMs (like LLaMA-2) but fine-tuned for Qwen’s needs.
Context Length: A standout feature is QwQ-32B’s extremely long context window. It supports up to 131,072 tokens of context huggingface.co venturebeat.com, which is about a 300-page book of text. This 128K+ token context length (achieved via a technique called YaRN – a RoPE scaling method huggingface.co) enables the model to ingest very large documents or multi-turn conversations far beyond the 4K–32K limits of typical LLMs. The long context is helpful for tasks like analyzing lengthy reports or maintaining extended dialogues without losing earlier information.
Training Data & Process: QwQ-32B builds on the Qwen-2.5 base model, which was pretrained on a massive dataset of 18 trillion tokens spanning diverse domains and multiple languages alibabacloud.com. The pretraining corpus includes web texts, books, code, and other data in 29+ languages (with strong emphasis on Chinese and English) alibabacloud.com, giving the model a broad knowledge base. After pretraining, the Qwen team applied supervised fine-tuning (SFT) on instruction-following data and then an intensive multi-stage reinforcement learning regimen huggingface.co venturebeat.com. In the first RL stage, the model was optimized for mathematical reasoning and coding tasks using outcome-based rewards – for example, an automatic math problem verifier to reward correct solutions and a code execution server to reward code that passes test cases qwenlm.github.io qwenlm.github.io. A second RL stage then trained the model on more general tasks (using a mix of reward models and rule-based checks) to improve instruction-following, alignment with human preferences, and “agent” abilities qwenlm.github.io. This RL-driven post-training is what distinguishes QwQ-32B from standard LLMs – it is specifically tuned to think step-by-step and adjust its reasoning based on feedback, rather than just predicting text from its pretraining distribution.
Unique Features: Thanks to its RL-based finetuning, QwQ-32B can generate a form of transparent chain-of-thought reasoning. Internally, it produces reasoning steps (enclosed in special <think> tags) followed by final answers huggingface.co. This design allows the model to engage in structured self-reflection and tool use – effectively giving it “agentic” capabilities where it can call tools or adjust its approach mid-generation based on intermediate results qwenlm.github.io. For example, QwQ-32B might perform calculations or transformations internally and only output the end result, or it can be configured to output its reasoning steps for developers to audit. Another feature is multilingual competence inherited from Qwen’s training: the model can understand and respond in many languages (Chinese, English, French, etc.), although most of its advanced reasoning benchmarks have been evaluated in English alibabacloud.com. Finally, QwQ-32B is released with full open-weight access (in contrast to closed models like GPT-4) – anyone can download the model files and run or finetune it locally qwenlm.github.io. This openness, combined with its technical innovations (long context, RL-tuned reasoning, tool-use integration), makes QwQ-32B a uniquely powerful and flexible LLM in the 30B-param class.
Performance Benchmarks
Qwen QwQ-32B has demonstrated impressive performance on reasoning-intensive benchmarks, often matching or surpassing much larger models. It was evaluated on a range of tasks in mathematics, coding, and logical reasoning to validate its capabilities qwenlm.github.io. Notably, the Qwen team compared QwQ-32B against DeepSeek-R1, a massive 671B-parameter model (37B active parameters via MoE) known for state-of-the-art reasoning qwenlm.github.io, as well as against distilled versions of DeepSeek and an “OpenAI-o1-mini” model (a reference smaller OpenAI model). Despite having only ~5% of the parameters of DeepSeek-R1, QwQ-32B delivers comparable results on these challenging benchmarks console.groq.com. This breakthrough indicates that scaling with reinforcement learning (and clever training) can yield disproportionate gains in reasoning ability – essentially achieving “big model” performance with a much smaller model footprint console.groq.com.
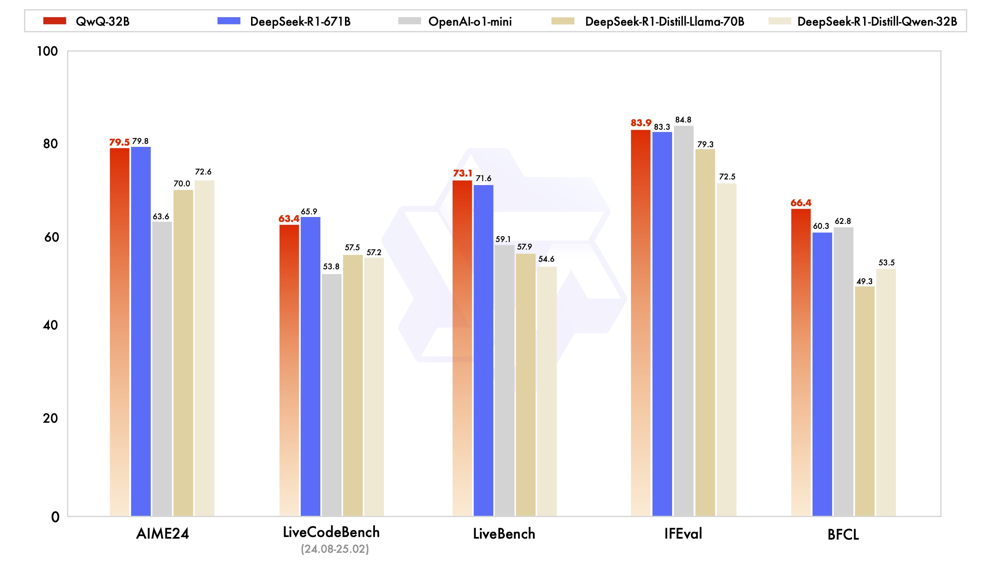
console.groq.com. Across diverse tests – AIME24 (math exam questions), LiveCodeBench (coding challenges), LiveBench (mixed tasks), IFEval (instruction-following evaluation), and BFCL (logical reasoning) – QwQ-32B matches or exceeds the performance of DeepSeek-R1 (blue, 671B) and comfortably outperforms OpenAI’s smaller “o1-mini” model (gray) and distilled models (beige tones). For example, on the AIME24 math benchmark QwQ-32B scored 79.5, virtually tied with DeepSeek’s 79.8 and much higher than the ~70 achieved by smaller models console.groq.com. On a general reasoning suite (LiveBench), QwQ-32B slightly outscored DeepSeek-R1 (73.1 vs 71.6), and on a logic-heavy task (BFCL) it led by a significant margin (66.4 vs 60.3) console.groq.com. The one area where QwQ-32B still trails the very best is coding: on LiveCodeBench, it scored 63.4, which is close to the distilled 70B model’s performance but a bit below DeepSeek-R1’s 65.9 console.groq.com.
In addition to these specialized benchmarks, QwQ-32B performs well on many standard LLM evaluations. It inherits strong general knowledge and language understanding from its Qwen pretraining, so it can handle tasks like MMLU (academic questions), C-Eval (Chinese exams), and HumanEval (coding) competitively for its size (exact figures for QwQ were not yet published, but earlier Qwen models of similar scale were already strong on these) github.com. The strengths of QwQ-32B clearly lie in complex reasoning: it excels at multi-step math problems, challenging logic puzzles, and code generation with reasoning – areas where it often matches models 2–20× its size console.groq.com console.groq.com. Its RL-honed thought process gives it an edge in solving hard problems that require step-by-step deduction or planning. Another strength is the huge context window: QwQ-32B can utilize long contexts to solve tasks like reading comprehension over very large documents, which many other models cannot handle as effectively (for instance, GPT-3.5/4 usually max out at 4K–32K tokens).
However, there are some weaknesses/limitations to note from the benchmarks and reports. Firstly, QwQ-32B, being “only” 32B parameters, may not have the breadth of factual/world knowledge that ultra-large models (like GPT-4 or DeepSeek-671B) possess – it can sometimes miss niche facts or require retrieval for very specialized queries reddit.com. Its creators and early users observed that programming tasks remained a challenge in some cases: OpenAI’s larger models still maintained an edge on certain coding benchmarks like LiveCodeBench venturebeat.com, meaning QwQ-32B might generate less efficient or less correct code for very complex tasks compared to best-in-class models. Another observed quirk was “language mixing” or circular reasoning in some outputs venturebeat.com – for example, the model might inadvertently switch languages mid-response or go into repetitive reasoning loops. These issues are likely due to the intricacies of the RL training and can often be mitigated by careful prompt formatting and decoding settings (the Qwen team recommends using a moderate temperature ~0.6 and avoiding greedy decoding to prevent loops huggingface.co console.groq.com). In summary, QwQ-32B’s performance is remarkably strong in reasoning and competitive with top models, but it may require knowledge augmentation for factual queries and careful tuning for tasks like coding, where it’s good but not yet the absolute leader.
Applications
Given its advanced reasoning skills and large context window, Qwen QwQ-32B is being applied to a wide array of use cases across industries. Below are some key applications and scenarios where QwQ-32B excels:
- Complex Problem-Solving & Math: QwQ-32B can tackle multi-step mathematical problems, logic puzzles, and scientific reasoning tasks with high accuracyconsole.groq.com. For example, it can work through competition math questions (like AIME/Olympiad problems) or logical brainteasers, showing its steps and explanations. This makes it valuable as a research assistant for scientists or as a tutoring AI for education, where showing the reasoning process is as important as the answer.
- Coding Assistance: The model demonstrates strong capabilities in code generation and debugging. It can write code, explain algorithms, and even perform step-by-step debugging of code snippetsconsole.groq.com. Developers can use QwQ-32B as an AI pair-programmer – for instance, to generate functions, suggest optimizations, or trace the cause of a bug by having it reason through the code. Its performance is comparable to much larger coder models on many programming challengesconsole.groq.com. With the extended context, it can ingest large codebases or API documentation (up to hundreds of thousands of tokens) to answer questions about system behavior or suggest integration code.
- Decision Support and Planning: Thanks to its reinforcement-learned “agentic” reasoning, QwQ-32B can assist in complex decision-making scenariosconsole.groq.com. It can weigh pros and cons, explore hypothetical scenarios, and generate strategic plans or recommendations. Businesses are exploring it for tasks like financial modeling and analysis – for example, feeding in large financial reports or market data and asking the model to analyze trends or forecast scenariosventurebeat.com. Similarly, it can support operations or logistics planning by evaluating various conditions and constraints in a long-form reasoning process.
- Customer Service & Chatbots: QwQ-32B’s strong instruction-following and multilingual ability make it a powerful conversational agent for customer support or information chatbots. It can handle complex user queries that require reasoning or reading through long knowledge bases. For instance, in customer service automation, it could be given a long chat history or user profile and still accurately address the user’s issue without losing contextventurebeat.com. Companies are interested in it for high-end chatbot applications where the queries might be technical or multi-part and require the bot to “think through” a solution (like troubleshooting guides, interactive FAQs, etc.). The fact that QwQ-32B can be self-hosted (unlike OpenAI’s models) also appeals to enterprises needing data privacy in customer interactionsventurebeat.com.
- Research and Content Analysis: With its 128K-token context, QwQ-32B is well-suited for research assistance and analysis of large documents. It can be tasked with reading and summarizing lengthy research papers, performing literature reviews (by synthesizing information from dozens of papers at once), or extracting key points from long legal contracts and regulatory documentsconsole.groq.com. Researchers can use QwQ-32B to brainstorm hypotheses or get explanations of complex concepts, as the model can draw on its extensive training knowledge and reason about it. In journalism or intelligence analysis, it could ingest a huge stream of articles or reports and answer detailed questions, making it a valuable tool for information synthesis.
These are just a few examples – generally, any application that benefits from deep reasoning, tool usage, or handling long content is a good fit for QwQ-32B. Early adopters have noted its potential in areas like financial modeling (scenario analysis, risk assessment)
venturebeat.com, education (solving and teaching solutions to problems), and even as a component in autonomous AI agents (for example, in an AI agent architecture, using QwQ-32B as the “brain” that plans actions and calls tools, given its ability to integrate feedback). Because QwQ-32B is open source, organizations are free to fine-tune it for domain-specific needs
venturebeat.com – we are seeing experiments in tuning it for medical reasoning, legal advice generation, and other specialized expert systems where step-by-step reasoning is crucial.
Usage and Availability
One of the advantages of QwQ-32B being open-source is the flexibility in how users can access and deploy it. Anyone can obtain and run QwQ-32B, provided they have sufficient hardware, or they can use cloud services/APIs that host the model. Here are key points regarding its usage and availability:
- Open-Weight Access: The full model weights for QwQ-32B are available for download on platforms like Hugging Face and ModelScope, under the permissive Apache 2.0 licenseqwenlm.github.io. This means developers can freely use the model for commercial or research purposes, and even fine-tune it on their own data without legal restrictionsventurebeat.com. The Hugging Face model repository provides the files in formats such as FP16, as well as optimized versions (e.g. int4/int8 quantized) for easier deploymentreddit.com. For instance, the Qwen team has released a GGUF quantized version that significantly reduces memory usage, allowing the model to run on a single high-end GPU or even multi-GPU setups with 16–24 GB VRAM per cardventurebeat.com. This is a stark contrast to its 671B-param competitor – running the full DeepSeek-R1 requires an array of 16 A100 GPUs and over 1.5 TB of VRAM, whereas QwQ-32B can operate on a single modern GPU like an NVIDIA A100 or H100venturebeat.com.
- Cloud APIs and Services: For users who don’t want to host the model locally, QwQ-32B is accessible via several cloud services. Alibaba Cloud provides an API endpoint for Qwen models through its DashScope service (an OpenAI-compatible API)qwenlm.github.io – developers can obtain an API key and query QwQ-32B in the cloud, similar to calling OpenAI’s API, but the inference is powered by Alibaba’s backend. Additionally, third-party platforms have integrated QwQ-32B due to its popularity: for example, OpenRouter (an open LLM routing service) offers QwQ-32B as a model option with a pay-as-you-go pricing (on the order of $0.15 per million input tokens)openrouter.ai. Hugging Face’s Inference Endpoint and HuggingChat have also deployed QwQ-32B; users can test the model directly in a web chat interface or via an API call with no setupventurebeat.com. This “one-click” deployment on Hugging Face means even non-technical users can spin up a QwQ-32B instance to chat with, and developers can integrate it into applications without managing infrastructureventurebeat.com.
- Interactive Chat and Demos: Alibaba has made a public demo called Qwen Chat (accessible at chat.qwen.ai) where QwQ-32B can be used in a conversational formatqwenlm.github.io. This is analogous to ChatGPT – users can enter prompts or questions and QwQ-32B will respond conversationally, leveraging its reasoning abilities. (Note: As with many Chinese cloud services, international access may require login or may have some restrictions, but the intent is to showcase the model’s capabilities interactively.) There are also community web demos on Hugging Face Spaces (and a Colab notebook) for QwQ-32B, making it easy to try out without any installation.
- Deployment and Usage Tips: To deploy QwQ-32B on-premise, one should have a capable hardware setup. The model in 16-bit precision requires ~65 GB of GPU memory, but with 8-bit or 4-bit quantization it can run in around 20–24 GB VRAMventurebeat.com, which puts it within reach of a single top-tier GPU (e.g., an RTX 6000 Ada 48GB can comfortably run it, or two RTX 3090s with 24GB each could split the load). The Qwen team provides optimized inference code and recommends using vLLM, a high-throughput inference engine, especially to utilize the long context efficientlyhuggingface.co. They also provide configuration for enabling the YaRN rope scaling in the model’s config for long inputshuggingface.co. Users should follow the usage guidelines: for example, when prompting the model in a chat format, the prompt should include the special
<s><|im_start|>...tokens or use the provided chat template to ensure the model produces the hidden<think>reasoning and the final answer properlyhuggingface.co. Sampling settings like temperature 0.6 and top_p 0.95 are advised to get the best quality (avoiding repetitive loops)huggingface.co. All these details are documented on the official Qwen GitHub and ReadTheDocs pages, with examples in Python for quick startqwenlm.github.io.
In terms of licensing, QwQ-32B being Apache 2.0 is a major advantage – it places no restrictions on use (unlike some other open models that have non-commercial clauses). This means companies can integrate QwQ-32B into their products or services without worries, and even fine-tune the model on proprietary data. Alibaba’s open approach here is notable, as even OpenAI’s GPT-3.5/GPT-4 are only accessible via API and not open weights. Users, however, should still be mindful of responsible AI use: running the model offline means it won’t have built-in content filtering unless the user adds one. The Qwen team has a moderation and usage policy in their documentation that they encourage users to follow (for example, avoiding harmful content generation). Overall, QwQ-32B is widely available and relatively easy to experiment with, both for hobbyists (who can use community servers or lightweight quantized versions) and enterprises (who can deploy it on their cloud or use Alibaba’s services). Its combination of power and accessibility is accelerating its adoption in various AI projects.
Challenges and Future Prospects
Current Challenges & Limitations: While QwQ-32B is a significant leap in reasoning ability for an open model, it is not without limitations. One challenge, as discussed, is that a 32B model has a more limited parametric memory than gigantic models – it occasionally lacks factual knowledge or context that larger models might “remember”. Users have noted that out-of-the-box it might not know very recent events or very obscure facts, which is expected given its training data cutoff and size. This can be mitigated by retrieval augmentation (feeding the model relevant text from a database when asking questions) reddit.com, effectively giving it an external memory. Another issue observed in early testing of QwQ-32B was the tendency for “chain-of-thought” verbosity or loops – since the model is trained to produce detailed reasoning, it sometimes over-explains or goes in circles if the prompt isn’t specific. The Qwen team addressed some of these in fine-tuning, but users are advised to use the recommended decoding settings to prevent infinite reasoning loops console.groq.com. There were also minor language mix-ups reported (e.g., a response that accidentally includes some Chinese text in an English answer) venturebeat.com, likely due to the multilingual training. This is being looked at for improvement in future versions, ensuring the model sticks to the language of the query unless asked to translate.
From a deployment perspective, latency and token consumption can be a challenge. QwQ-32B’s detailed reasoning means it often produces a lot of “thinking” tokens (which might be hidden from the user, but they still count in processing) – this can make inference slower and consume more compute reddit.com venturebeat.com. Running with the full 128K context, while supported, is computationally heavy (in practice, very long inputs will slow down generation and require more memory or distributed computing). The Qwen team notes that the long context mode (via rope scaling) should be enabled only when neededhuggingface.co because it can slightly affect performance on short prompts (a fixed scaling factor might dilute precision on smaller inputs). Also, being a new model, community tooling is still catching up – e.g., not all inference frameworks immediately supported the <think> parsing, though this is quickly being integrated by the open-source community.
Another consideration is ethical and security concerns: As the VentureBeat analysis pointed out, some users or organizations might be cautious adopting a model from a Chinese tech giant venturebeat.com. They might worry about biases in training data or any latent content moderation embedded by the creators. However, because QwQ-32B can be run completely offline, one can audit its outputs and even fine-tune it to address biases, which is actually an advantage over using a black-box API. So far there have been no specific red flags in QwQ-32B’s behavior reported, but as with any LLM, it may reflect biases present in its training data and can produce incorrect or nonsensical answers if prompted adversarially. Users deploying it in critical applications should thoroughly test and possibly finetune the model for their domain to ensure reliability and alignment with desired values.
Future Prospects: The introduction of QwQ-32B is described by its creators as just the “initial step” in a larger roadmap towards more intelligent and general AI systems qwenlm.github.io. Going forward, we can expect several developments:
- Scaling Up RL and Model Size: The Qwen team plans to explore scaling the reinforcement learning approach to even larger models and more stepsventurebeat.com. This could involve training a QwQ variant of the 70B or 100B-scale Qwen model, which might further close the gap to human-level reasoning and perhaps challenge models like GPT-4 outright. Also, more RL training (more episodes or additional stages) could continue to improve the 32B model itself or yield new emergent abilities.
- Long-Horizon “Agent” Integration: A major research direction is integrating agentic behavior with RLqwenlm.github.ioventurebeat.com. This means future Qwen models might better handle tasks that require planning actions over a long dialogue or process (so-called long-horizon reasoning). They might interface more seamlessly with external tools (search engines, calculators, databases) during generation, learning when to invoke a tool and how to use the results in their reasoning. This would make them even more capable problem solvers (e.g., solving a complex task by breaking it into sub-tasks, gathering information, and so on autonomously).
- Enhanced Base Models (Qwen 3.0?): Alibaba will continue to improve the foundation models that QwQ builds on. The Qwen2.5 series introduced massive token pretraining and long context; future versions may push context lengths to 1 million tokens and beyond (indeed, Alibaba already showcased an experimental 1M-token model) and incorporate new training data to expand knowledgealibabacloud.com. There is also interest in model efficiency – techniques like mixture-of-experts (MoE) or sparse activations could be used to keep model size manageable while increasing effective capacity. If a QwQ-72B or similar is released, it could potentially set new records in open-model performance.
- Towards AGI: Loftier, the Qwen team explicitly mentions their aim of moving closer to Artificial General Intelligence through these effortsqwenlm.github.io. This involves not just making the model larger or better at benchmarks, but also more robust, adaptive, and autonomous. We might see Qwen models that learn continually from interactions (online learning), or that have improved common-sense and self-correction abilities. The combination of a “stronger foundation model + scaled RL” is viewed as a key recipe to inch toward AGI-level systemsqwenlm.github.io, and QwQ-32B is a proof-of-concept that this recipe works well.
In summary, Qwen QwQ-32B has opened a promising path for the LLM field: it showed that with clever reinforcement learning and engineering, a relatively moderate-sized model can achieve top-tier reasoning performance. The current challenges (knowledge scope, minor generation quirks, compute needs for long contexts) are being actively addressed by ongoing research. The community can likely look forward to more advanced QwQ models and perhaps a whole new class of “Large Reasoning Models” that emphasize reasoning quality over sheer parameter count venturebeat.com. This shift – focusing on how an AI thinks, not just how much it memorized – could lead to more efficient and generally capable AI systems. QwQ-32B, with its open-source release, is catalyzing experimentation in this direction and is positioned as a foundation for future breakthroughs in general AI problem-solving venturebeat.com.
References: Qwen QwQ-32B blog announcement qwenlm.github.io qwenlm.github.io; Qwen2.5 technical report alibabacloud.com alibabacloud.com; HuggingFace model card huggingface.co huggingface.co; VentureBeat coverage venturebeat.com venturebeat.com; Groq model documentation console.groq.com console.groq.com; Alibaba Cloud Qwen docs alibabacloud.com; Reddit discussions on QwQ-32B usage reddit.com.