Introduction
On March 5, 2026 (US time), OpenAI released GPT-5.4 across three surfaces at once: ChatGPT (as “GPT-5.4 Thinking”), the OpenAI API (as gpt-5.4), and Codex. In the same rollout, OpenAI also introduced a higher-end variant, GPT-5.4 Pro (gpt-5.4-pro), positioned for maximum performance and deeper reasoning on complex workloads.
The release matters less as a single “bigger model drop” and more as a consolidation step in OpenAI’s GPT-5 line: GPT-5.4 is explicitly framed as the first “mainline reasoning model” that absorbs the frontier coding capabilities previously shipped in GPT-5.3-Codex—while simultaneously upgrading “agentic” execution across tools, software environments, and professional deliverables (spreadsheets, presentations, and documents).
In practical terms, OpenAI’s March 2026 cadence looked like a tightly linked sequence rather than a single announcement: GPT-5.3 Instant (March 3) targeted everyday conversational flow and refusal tone; Codex app and other workflow features landed in early March; and GPT-5.4 (March 5) aimed to become the professional “do-the-work” brain that spans coding, web research, tool ecosystems, and (notably) native computer-use.
Public signals from leadership and official channels amplified the framing. Sam Altman posted on X (Twitter) that GPT-5.4 was not only strong at coding and knowledge work but also his “favorite model to talk to,” explicitly tying the release to personality and conversational feel—an area where OpenAI had acknowledged prior friction with the GPT-5 era’s tone.
Technical characteristics of GPT-5.4
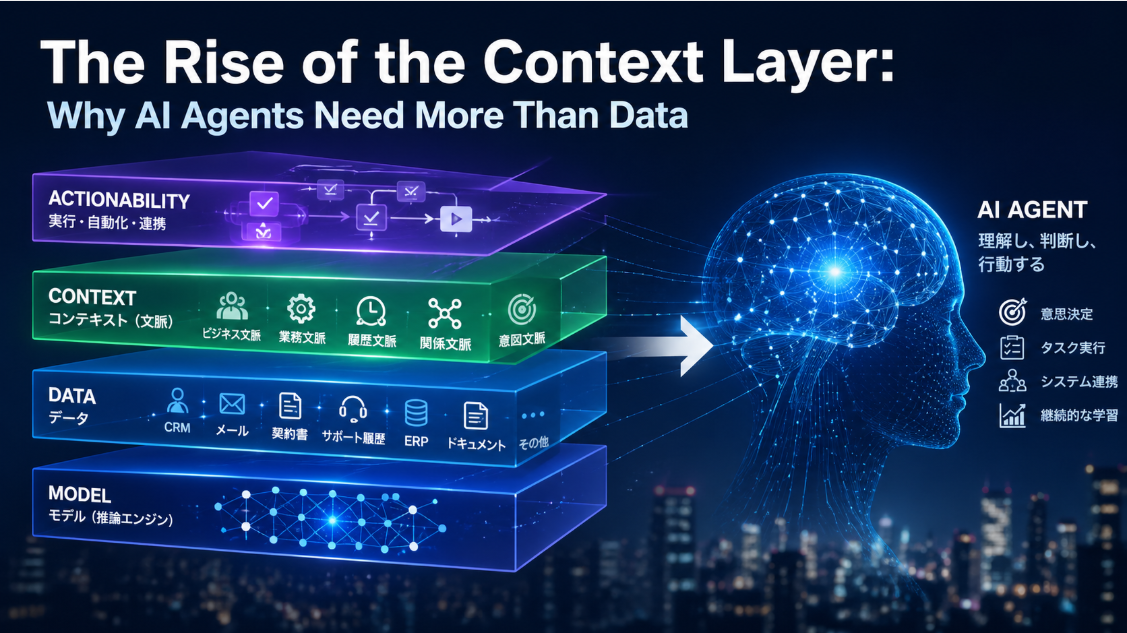
GPT-5.4 is best understood as a “workflow frontier” model: not merely higher benchmark scores, but a set of capabilities meant to keep an agent on-task over longer horizons, in tool-heavy environments, under real operational constraints (latency, token budgets, risky actions, and adversarial inputs). OpenAI’s official “Using GPT‑5.4” developer guide lists the key improvements relative to GPT-5.2 as advances in coding, document understanding, tool use, instruction following, image perception, long-running task execution, token efficiency in tool-heavy workloads, and agentic web search/multi-source synthesis.
One technical anchor is variant design and “reasoning effort” control. In the API, gpt-5.4 supports reasoning.effort from none (default) up through xhigh, while GPT-5.4 Pro is positioned as the slowest, deepest-thinking variant, supporting reasoning.effort values including medium/high/xhigh. This reinforces OpenAI’s broader GPT-5 design philosophy (first articulated when GPT-5 launched in August 2025): mixing “think longer when needed” with practical routing and product defaults.
A second anchor is context length and context management. GPT-5.4’s API “hard contract” lists a 1,050,000-token context window and up to 128,000 output tokens for GPT-5.4 Pro, with a knowledge cutoff of August 31, 2025. OpenAI further states that Codex includes experimental support for a 1M context window, controllable via model_context_window and model_auto_compact_token_limit, and that requests exceeding the standard 272K window count against usage limits at 2×. Pricing documents confirm a parallel billing structure: for 1.05M context models, the listed pricing applies below 272K input tokens, while prompts above 272K are priced at 2× input and 1.5× output for the full session (and reasoning tokens—though not visible—are billed as output).
A third anchor is “native computer use,” which OpenAI highlights as a turning point: GPT-5.4 is framed as the first general-purpose OpenAI model released with native, state-of-the-art computer-use capabilities to move across applications using screenshots plus keyboard/mouse actions. The OpenAI computer use guide describes the mechanics: models can request screenshots, then emit action batches like click/double-click/scroll/keypress/type, enabling a build–run–verify–fix loop for agents that operate inside real UI surfaces. The same guide explicitly ties implementation to product safety design: developers should confirm at the point of risk (e.g., before submitting sensitive data or performing irreversible actions), and treat confirmation policy as a core part of the system rather than an afterthought.
A fourth anchor is scaling to large tool ecosystems. OpenAI introduced “tool search” in GPT-5.4 as a mechanism for deferred tool loading: instead of front-loading every tool definition into every prompt (which can add thousands or tens of thousands of tokens), the model receives a lightweight tool inventory and uses tool search to fetch definitions only when needed, preserving cache efficiency and lowering cost/latency. The tool search documentation is explicit that only gpt-5.4 and later support this capability and provides two modes: hosted tool search (OpenAI performs the lookup) and client-executed tool search (your application returns the matching tool definitions to the model).
This “tool ecosystem” framing connects to the Model Context Protocol (MCP), the emerging connector/tool standard that OpenAI now positions as a primary way to attach models to external systems. OpenAI’s MCP documentation describes MCP as “an open protocol” becoming an industry standard for extending models with tools and knowledge via remote servers. The protocol’s original push into mainstream AI tooling is also historically associated with Anthropic, which introduced MCP as an open standard in late 2024. GPT-5.4’s tool search and MCP orientation can be read as OpenAI optimizing for a world where “AI work” is mediated by large inventories of connectors and tools rather than a small set of built-in functions.
Finally, OpenAI’s GPT-5.4 Thinking System Card frames the release in deployment-safety terms. It states that GPT-5.4 Thinking is the first general-purpose model in the series to have implemented mitigations for “High capability in Cybersecurity,” building on earlier GPT-5.3 Codex cyber safeguards. This matters because it links technical capability increases (especially tool use and computer use) to both broader safety evaluations and stricter operational safeguards, including the risk of false positives that can confront legitimate development work.
Major updates and improvements
From OpenAI’s own narrative, GPT-5.4 is less a “single-axis intelligence bump” and more a multi-capability integration release: it pulls together reasoning work from GPT-5.2, coding improvements from GPT-5.3-Codex, and “agent workflow” improvements across tool use, web research, and computer operation. In that framing, the key upgrades cluster into five areas.
First is professional knowledge work quality. OpenAI reports that on GDPval—an evaluation spanning well-specified knowledge work across 44 occupations—GPT-5.4 “matches or exceeds” industry professionals in 83.0% of comparisons, compared with 70.9% for GPT-5.2. OpenAI also claims that on presentation evaluation prompts, human raters preferred GPT-5.4’s presentations 68.0% of the time over GPT-5.2, attributing the preference to stronger aesthetics, more visual variety, and better use of image generation.
Second is computer-use performance, which OpenAI positions as “human-competitive.” On OSWorld-Verified, OpenAI reports GPT-5.4 reaches a 75.0% success rate, far above GPT-5.2’s 47.3% and slightly above a cited human baseline of 72.4%. This claim is operationally significant because it implies the model can execute multi-step tasks across real desktop environments—not just answer questions about them.
Third is coding and “agentic coding workflows.” OpenAI’s published eval table shows GPT-5.4 at 57.7% on SWE-Bench Pro (public) versus GPT-5.2 at 55.6%, and a large jump on Terminal-Bench 2.0 (75.1% vs 62.2%), while GPT-5.3-Codex remains slightly higher on Terminal-Bench (77.3%). The pattern is consistent with the “integration” story: GPT-5.4 tries to bring frontier coding skill into a generalist reasoning model, while Codex-specialized checkpoints can still edge it out on some agentic terminal tasks.
Fourth is tool-use scaling and web research. OpenAI highlights BrowseComp (agentic browsing) as a major gain: GPT-5.4 rises to 82.7% from 65.8% for GPT-5.2, while GPT-5.4 Pro hits 89.3%. The ChatGPT release notes add a user-facing version of the same story: GPT-5.4 Thinking improves deep web research for highly specific queries and maintains context better for tasks requiring longer thinking. Tool search is the cost/latency lever that makes this more viable at scale. OpenAI reports a 47% reduction in total token usage on 250 tasks from Scale’s MCP Atlas benchmark when placing MCP servers behind tool search—while keeping accuracy the same.
Fifth is steerability and mid-response control in ChatGPT. OpenAI states that GPT-5.4 Thinking can outline its plan (a “preamble”) for longer complex queries and that users can adjust instructions mid-response to guide the model without restarting. OpenAI also specifies rollout: web and Android first, iOS later. This should be read as a UX adaptation to longer-horizon reasoning models: if responses take longer and involve multiple steps, users need a tighter control loop than “prompt–wait–retry.”
Alongside these model-level upgrades, OpenAI shipped product integration that signals where GPT-5.4 is meant to create business value: spreadsheets. On March 5, OpenAI announced ChatGPT for Excel (beta) and new financial data integrations, positioning the feature as a way to build, update, and analyze spreadsheets directly inside Excel—while also previewing that ChatGPT for Google Sheets is “coming soon.” The official product page notes that access is limited by plan and geography in beta (U.S., Canada, Australia) and that Enterprise/Edu/Teacher workspaces default to off, with admin enablement via roles and permissions.




Summary of media coverage
Media coverage of GPT-5.4 largely followed OpenAI’s own framing—professional work, agentic automation, and tool integration—but outlets differed in what they treated as “the headline.” Some centered the model’s agent capabilities (computer use), others centered enterprise workflow (Excel/finance integrations), and others centered the competition narrative (especially the coding-agent race against Claude Code).
The table below summarizes how major international and Japanese outlets emphasized different angles in the first week after the March 5, 2026 release. The descriptions are based on each outlet’s reporting and the specific details they foregrounded (for example: the 1M context window, Pro/Thinking differentiation, spreadsheet tools, competitive positioning, and “personality” issues).
| Outlet | Region | What the coverage foregrounded |
|---|---|---|
| TechCrunch | International | The release structure (Thinking/Pro), flagship positioning for professional work, and the large context-window claim, treating the API/Codex rollout as a major practical upgrade. |
| Bloomberg | International | Financial workflow integrations and reduced “back-and-forth” for office tasks, reflecting enterprise/finance readership and competition with AI products aimed at business workflows. |
| WIRED | International | A broader “coding agent race” narrative: OpenAI’s push to catch up in AI coding agents and why coding workflows matter strategically. |
| TechRadar | International | Practical consumer framing: “Thinking” upgrade in ChatGPT, the spreadsheet angle, pricing signals, and leadership commentary on remaining weaknesses. |
| Tom’s Guide | International | Hands-on style evaluations and speed framing (e.g., portraying GPT-5.4 as a meaningful usability upgrade rather than a subtle benchmark bump). |
| ITmedia | Japan | “PC操作” (native computer use) as the defining shift, plus long context and agent workflows; some coverage also treated GPT-5.4 as a step toward “やり抜くAI” (agents that finish). |
| Impress Watch | Japan | Rollout specifics (plans, replacement of GPT-5.2 Thinking), Pro availability, and productization details (API model names, Codex availability). |
| ASCII.jp | Japan | A benchmark-and-impact framing, highlighting “human-level or better” claims in computer-use tasks and professional task performance. |
| Nikkei | Japan | Business positioning (Excel linkage) and competitive comparison with Anthropic in performance framing (as reflected in Nikkei’s shared headlines/snippets). |
Two reporting contrasts stood out. First, business-facing outlets treated GPT-5.4 as “office automation infrastructure” rather than a chatbot upgrade—especially through the Excel/financial-data integrations and the promise of fewer iteration loops. Second, developer-facing narratives (including WIRED’s and several Japanese developer-community writeups) treated the release as a move toward autonomous coding and cross-application agents, with “computer use” and long context as the enabling primitives.
A practical limitation of this research: direct access to some Japanese coverage was constrained. For example, CNET Japan pages were blocked by robots.txt in this environment, preventing direct review of CNET Japan reporting; and some Nikkei article text appears paywalled, so only shared headline snippets (e.g., from Nikkei’s social posts) were accessible.
Expert and user reactions
Public reactions formed quickly—and split along a familiar line for frontier-model releases: “This changes what I can automate” versus “This changes what breaks in my workflow.” The most revealing reactions came from developers and power users, because GPT-5.4’s value proposition depends on sustained multi-step execution (agents, tools, long contexts), and those users hit edge cases first.
On social platforms, one of the most-cited “positive affect” signals was Sam Altman’s X post praising GPT-5.4 not only for capability but for conversation—suggesting OpenAI was trying to reclaim “chat feel” alongside professional power. OpenAI’s own release notes reinforced the UX shift: in ChatGPT, GPT-5.4 Thinking can provide an upfront planning preamble and accept mid-response corrections, a feature explicitly designed to reduce restarts and extra turns.
On X, praise and critique often appeared in the same thread: power users praised the step-by-step competency while flagging friction around UI generation quality (“frontend taste”), tool integrations, and model consistency. This blend of excitement and “the rough edges are obvious” matches OpenAI’s own positioning that GPT-5.4 is aimed at professional work, where iteration cost matters.
On Hacker News, developers framed the question less as benchmark supremacy and more as task-level preference versus rivals. A representative comment captured both sides: GPT-5.4 felt better for some real coding work, while a competitor “talks” better and produces nicer output formatting in some tools.
On Reddit, threads specifically comparing “first impressions” of GPT-5.4 included mixed experiential reports: some users praised speed or capability compared with GPT-5.2, while others complained about overanalysis, slowness, or an “oversmart vibe” that makes it harder to steer in day-to-day work. A representative excerpt (Reddit, quoted verbatim) illustrates the tone:
“Still getting the same oversmart vibe from it… Quite unpleasant to work with… Capability wise it definitely feels good.”
Other Reddit reports focused on usage/rate-limit burn and the interaction between higher-effort modes (including /fast usage patterns in Codex/agent tooling) and quota exhaustion—an issue that becomes salient precisely because GPT-5.4 is marketed for long, tool-heavy trajectories.
YouTube reaction content tended to be rapid-turnaround: “what’s new” explainers, early demos, and “prompt tests” that try to compress the model’s value into concrete workflows (planning, multi-step reasoning, coding tasks, document synthesis). Meanwhile, Japanese developer-community posts (for example on Qiita) quickly synthesized the official claims into practical checklists (computer use, 1M context, hallucination reductions) and guidance on where the upgrade matters in daily engineering work.
Finally, a “community feedback loop” emerged around safety measures, especially cybersecurity safeguards. Users surfaced error banners indicating temporary limitations due to potentially suspicious cybersecurity activity—often while insisting the work was normal development. This directly mirrors OpenAI’s own warning that the cyber safety stack can produce false positives during calibration and that a small portion of traffic may be affected.
Criticism and debates
The sharpest debates around GPT-5.4 cluster into four themes: cost/limits, safety gating and false positives, agent risk (especially computer use), and “personality/UX consistency.”
Cost and limits became a central topic because GPT-5.4’s marquee features (computer use, long context, tool-heavy agents) are also the most token- and time-intensive. Official pricing places gpt-5.4 at $2.50 per 1M input tokens and $15 per 1M output tokens (with cached input discounts), while gpt-5.4-pro is dramatically higher at $30 input and $180 output per 1M tokens. Moreover, OpenAI’s pricing explicitly penalizes “very long context” usage: sessions with >272K input tokens are priced at 2× input and 1.5× output, which makes 1M-context workflows plausible but economically nontrivial.
GPT-5.4 Pro drew a second-order debate about product segmentation. In OpenAI’s model documentation, GPT-5.4 Pro is “Responses API only,” may take minutes to finish, and suggests using background mode to avoid timeouts—i.e., it is positioned more like a work job than a synchronous chat. This raises a strategic question: is the “best” model still a conversational product, or is it becoming a background compute layer you orchestrate?
The second debate was safety gating, particularly cybersecurity. OpenAI’s GPT-5.4 blog states GPT-5.4 is treated as “High cyber capability” under its Preparedness Framework, with protections documented in the system card, and warns that some false positives may occur as classifiers are refined—especially for some customers on Zero Data Retention surfaces where request-level blocking remains part of the mitigation stack. Developers’ real-world complaints (GitHub issues and forum posts) provide concrete examples of how that friction manifests: accounts flagged for “potentially high-risk cyber activity,” with requests routed to less capable fallback models, and instructions to apply for trusted access. OpenAI’s own cybersecurity checks documentation anticipates this, explicitly noting that legitimate defensive work can be flagged while systems are still being calibrated.
The third debate followed from “computer use”: if an AI agent can click buttons and type into real systems, safety is no longer only about content—it is about action. OpenAI’s system card highlights evaluations for avoiding accidental data-destructive actions and describes updated training for user confirmations: instead of a single fixed confirmation behavior, the model is trained to follow both a platform policy for high-risk actions and a configurable developer-provided confirmation policy via the developer message. The computer use guide reinforces the same design approach: confirm “immediately before the next risky action,” especially for sensitive data or irreversible steps. Critics essentially argue that this turns “agent UX” into a governance problem: if confirmation prompts are too frequent, agents are slow and annoying; if they are too rare, errors can become costly.
The fourth debate was “personality and instructional drift”—a theme that OpenAI itself acknowledged in GPT-5.3 Instant’s release narrative (reducing preachiness, fewer unnecessary refusals, smoother tone) and that leadership commentary revived with GPT-5.4. Some users welcomed the perceived improvement in conversational feel; others surfaced quirky artifacts (for example, a Hacker News thread joking about a “goblin/gremlin” verbal tic after the 5.4 update). These may seem trivial, but historically such artifacts become proxies for deeper dissatisfaction: users interpret them as “loss of control” over style, or evidence the model is overfit to some RL preference pattern.
Impact on the AI industry
GPT-5.4’s industry impact is best framed as a competition over workflow ownership rather than raw language-model prowess. The model’s headline features—computer use, tool search, MCP-scaled connectors, spreadsheets/docs/presentations—align directly with enterprise productivity software and developer automation.
In the coding space, the competitive backdrop is explicit. WIRED’s reporting describes an internal OpenAI push to catch up in the AI coding market as rivals gained traction, with coding agents becoming a cornerstone of application strategy. The “Using GPT‑5.4” guide further frames GPT-5.4 as the default model for broad general-purpose work and most coding tasks, replacing gpt-5.2 in the API and gpt-5.3-codex in Codex—an OpenAI attempt to unify the developer experience around one flagship that can both reason and code in the same workflow.
Competitors responded (or, in some cases, had already moved). Anthropic’s Claude Opus 4.6 release in February 2026 emphasized improved coding skills, longer-horizon agentic tasks, and a 1M token context window (beta)—a remarkably similar “agentic coding + huge context” thesis. Google’s Gemini 3.1 Flash-Lite (March 3, 2026) took the opposite strategy: rather than pushing frontier reasoning depth, it targeted speed and cost efficiency for high-volume workloads, with explicit token pricing and deployment via Gemini API/AI Studio and Vertex AI. And in xAI’s ecosystem, broader AI-agent ambitions have been described in mainstream reporting as combining an LLM “navigator” with a separate agent that processes screen video and input controls—underscoring that “computer-operating agents” have become a competitive primitive, not an OpenAI-only bet.
In enterprise productivity, GPT-5.4’s Excel integration is the clearest tell. OpenAI’s product announcement positions ChatGPT for Excel as a way to build/update/analyze spreadsheets inside Excel, while also coupling it with new financial data integrations inside ChatGPT—an explicit attempt to embed GPT output into the artifacts executives actually use (models, tables, forecasts). Bloomberg’s framing aligns with this: GPT-5.4 is reported as better at spreadsheet/document/presentation tasks with less user back-and-forth, and the outlet treated the release as part of an enterprise tools push rather than a consumer chatbot story.
In platform architecture, GPT-5.4 reinforces a structural shift: the “agent ecosystem” is becoming standardized and connector-driven. OpenAI describes MCP servers and connectors as the mechanism to extend models to new data sources and tools, and tool search is a specifically engineered solution to make such ecosystems economically feasible at scale. The existence of Scale’s MCP-Atlas benchmark—and OpenAI’s use of it as a public evaluation target—suggests tool-use competency is now sufficiently important to earn its own standardized benchmark layer.
Finally, GPT-5.4’s cyber mitigations show how competition and regulation pressures are co-evolving. OpenAI’s official system card positions GPT-5.4 Thinking as the first general-purpose model with “High cybersecurity capability” mitigations, and OpenAI is simultaneously piloting trust-based access frameworks to reduce friction for legitimate defenders while limiting misuse. This is not just “safety messaging”—it is a market-shaping move: as more models become cyber-capable, vendors are differentiating on access governance, auditability, and friction management as much as on raw capability.
Overall evaluation and outlook
GPT-5.4’s release is best characterized as a consolidation and operationalization step in the GPT-5 line. GPT-5 (August 2025) introduced the “built-in thinking” paradigm and a unified-system story; GPT-5.2 (December 2025) pushed hard into professional knowledge work and agentic tool calling; GPT-5.3 Instant (March 3, 2026) targeted everyday conversational feel and reduced refusals; GPT-5.3-Codex (February 2026) sharpened agentic coding performance; and GPT-5.4 (March 5, 2026) aims to fuse these threads into one flagship professional model with native computer use and scalable tool ecosystems.
As an enterprise AI platform, GPT-5.4’s most meaningful advances are not a single benchmark number but the “systems” features: tool search for large tool inventories, compaction for long trajectories, computer-use guidance that treats confirmations as a first-class design element, and product integrations like Excel that move from “chat about work” to “work inside the artifact.” These features reduce the operational tax of deploying AI agents: they are designed to lower token overhead, preserve cache, manage context growth, and reduce the iteration loop between users and the model.
For ChatGPT end users, the most tangible UX change is steerability during long responses: the planning preamble and the ability to adjust course mid-response. If it works reliably, it could compress what used to be 3–6 prompt iterations into a single “guided generation” pass—one of the clearest forms of practical model improvement beyond raw intelligence. However, community feedback suggests this comes with tradeoffs: longer or more “overthinking” behavior can feel slow or controlling to users who want lightweight answers, and quota/limit burn becomes more salient when a model is optimized to take longer trajectories.
Relative to competitors, GPT-5.4’s strategy sits between two poles. On one side, Anthropic’s recent releases emphasize long-horizon agentic coding and very large context windows; on the other, Google’s Flash-Lite tier emphasizes cost-efficient high-volume throughput. GPT-5.4 tries to compete “in the middle”: frontier capability that is still operationally efficient through token efficiency and deferred tool loading, plus a product surface (ChatGPT/Codex/Excel) intended to capture day-to-day professional workflows.
A reasonable near-term outlook is that GPT-5.4 accelerates a broader directional change: ChatGPT becomes less a single chat interface and more a layered work platform (agents, apps, connectors, spreadsheets, long-running background jobs), while “model releases” become less about a new name and more about which workflow primitives become stable and widely usable. The biggest open risks will likely remain the same ones surfaced in the first wave of reactions: cost management under long-horizon usage, reliability under tool-heavy autonomy, and safety systems that minimize real harm without forcing too many legitimate users into false-positive enforcement paths.