Executive summary
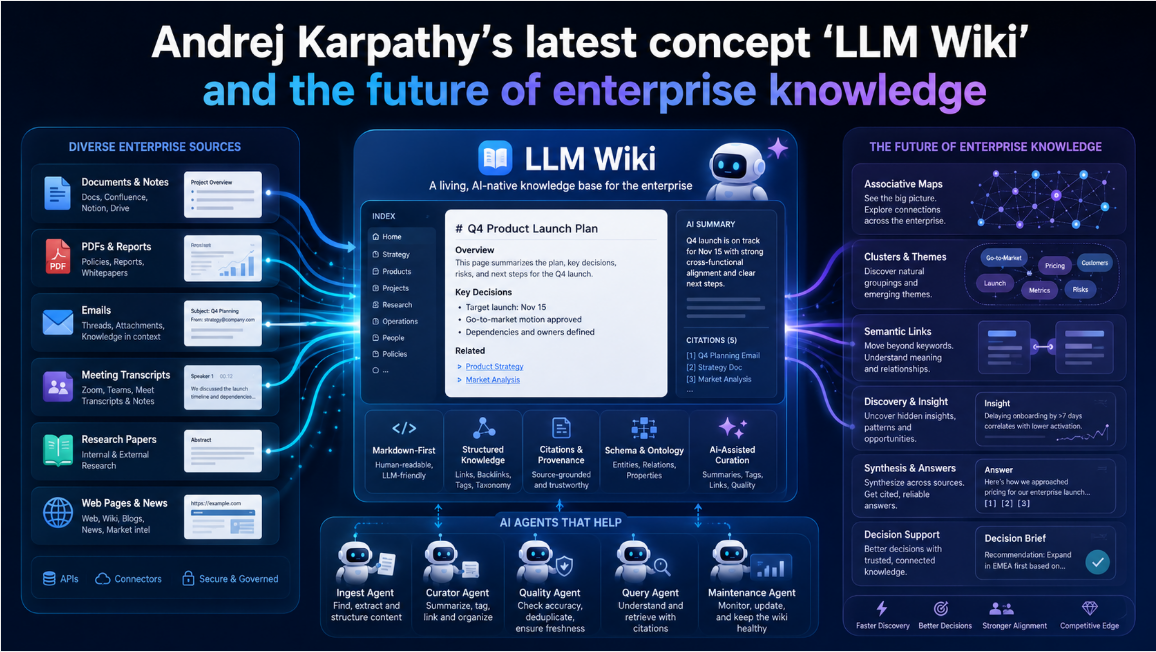
Andrej Karpathy’s public GitHub Gist, published on April 4, 2026, describes LLM Wiki not as a finished product, but as an “idea file” for agentic knowledge work: instead of re-retrieving raw fragments on every question, an LLM incrementally compiles curated source material into a persistent, interlinked Markdown wiki, guided by a schema file such as CLAUDE.md or AGENTS.md. In Karpathy’s pattern, the core stack is raw sources as immutable truth, a wiki as the maintained knowledge layer, and a schema as the operating contract for ingest, query, and maintenance. The practical promise is compounding knowledge: each ingest and each good answer can strengthen the corpus rather than vanish into chat history. (1)
The investor page from treats that pattern as a transition point rather than an endpoint. Its Self-Organizing Wiki vision keeps original enterprise documents as the source of truth, treats the LLM Wiki as an AI-generated structured knowledge layer, and adds ConceptMiner plus a ThinkNavi interface to discover concept clusters, bridge concepts, structural analogies, and knowledge gaps. Read conservatively, this is a roadmap and market thesis, not proof of a fully shipped enterprise platform. Analytically, the strongest conclusion is that LLM Wiki is best seen as a knowledge-compilation layer that complements retrieval, while Self-Organizing Wiki is an attempt to add structural discovery and associative exploration on top of that layer. (1)
What LLM Wiki is
Karpathy’s core claim is simple: most document-centric LLM workflows still behave like retrieval-augmented generation, where the model finds relevant chunks at query time and reconstructs the answer from scratch each time. LLM Wiki shifts the heavy knowledge work earlier. A new source is not just indexed; it is read, summarized, linked into existing entity and concept pages, reconciled against prior claims, and recorded in a persistent wiki that the human primarily reads while the model primarily maintains. Karpathy’s three-layer architecture is explicit: raw sources are immutable and remain the source of truth; the wiki is an LLM-generated Markdown layer composed of summaries, entity pages, concept pages, comparisons, overviews, and syntheses; the schema tells the agent how to structure the wiki and how to execute ingest, query, and maintenance workflows. (1)
That architecture also defines a division of labor. Karpathy’s formulation is that the human curates sources, explores, and asks the right questions, while the LLM performs the persistent bookkeeping: summarizing, cross-referencing, updating, and filing. He explicitly lists personal self-tracking, topic research, book companions, business/team knowledge, and due diligence as candidate use cases, and he frames Markdown plus local browsing tools as the working environment in which the wiki becomes a durable artifact rather than a transient chat output. (1)
How it differs from RAG
Conventional RAG, in official documentation, processes a knowledge base into searchable vector or other retrieval structures and, when a user asks a question, retrieves relevant passages and provides them to the model to ground the answer. LLM Wiki changes the timing of synthesis. The main distinction is therefore ingest-time compilation versus query-time assembly. In RAG, freshness is relatively strong because new documents can be retrieved as soon as they enter the index. In LLM Wiki, coherence is stronger because cross-document synthesis can already exist before the question is asked, but freshness depends on how quickly the wiki is re-ingested and maintained. (2)
This timing difference clarifies the comparison with nearby systems. GraphRAG still centers on an indexing pipeline plus a query engine: it extracts entities, relationships, claims, community summaries, vectors, and then answers questions over completed indexes through local, global, DRIFT, or basic search. That is more structured than baseline RAG, but still fundamentally query-oriented. NotebookLM remains source-grounded at answer time: its help pages emphasize inline citations, source selection, and grounded answers based on uploaded sources or static source copies. Projects in ChatGPT are different again: they are long-running workspaces that keep chats, files, instructions, memory, and tools together, but the official description does not position them as autonomous wiki compilers. So LLM Wiki is not simply “better RAG”; it is a different design target: persistent knowledge artifacts first, retrieval second. The last clause is a synthesis from the cited materials and should be read as an interpretive comparison. (3)
Architecture and operations
Karpathy’s public spec names three primary operations: ingest, query, and lint. Ingest reads a new raw source, discusses key takeaways with the human if desired, writes a summary page, updates relevant entity and concept pages, updates index.md, and appends an entry to log.md; Karpathy notes that a single source can touch 10–15 pages. Query starts from the index, reads relevant pages, synthesizes an answer with citations, and can save that answer back into the wiki as a new page. Lint performs health checks for contradictions, stale claims, orphan pages, missing concept pages, missing cross-references, and data gaps worth filling with new searches. index.md is content-oriented navigation; log.md is chronological, append-only operational history. Karpathy also notes that this works “surprisingly well” at moderate scale and that the wiki itself can live as a Git-backed Markdown repository, which naturally gives version history and rollback. (1)
What Karpathy’s Gist does not specify is equally important. It does not define a canonical parser, normalization stack, chunking policy, citation schema, merge algorithm, or audit model. So when people now talk about ingest internals such as parsing, normalization, chunking, and citation capture, those are mostly implementation details added by follow-on tools rather than fixed parts of Karpathy’s public spec (inference). Community implementations illustrate the gap. The llm-wiki-compiler project adds multimodal ingest, chunked retrieval with reranking, paragraph- and claim-level provenance, typed page kinds, candidate review queues, contradiction metadata, linting, and rollback-oriented roadmap items. adds log.md, structured JSON logs, and an append-only audit.db, with source hashes, cost records, job history, cache invalidation on file hash change, and audit queries. adds approval bundles, contradiction detection, provenance-tracked graph edges, context packs, and hybrid search. makes the vault structure itself explicit with raw/, wiki/, outputs/, and SCHEMA.md. (5)
The agent workflow implied by the public pattern is concrete enough to describe at file level. A typical Obsidian + agent loop is: use Obsidian Web Clipper to capture a web page into Markdown; save article content and metadata into raw/; let the agent generate or revise wiki/sources/<source>.md, wiki/concepts/<concept>.md, and wiki/entities/<entity>.md; update wiki/index.md and wiki/log.md; then inspect the graph and backlinks in Obsidian, where internal links are navigable and can auto-update when files are renamed. Karpathy explicitly describes browsing the results in real time with Obsidian open beside the agent. Obsidian’s Web Clipper supports templates, variables, and Markdown extraction of page content, while Graph view visualizes node-link relationships inside the vault.(1)
With Claude Code, the wiki pattern maps naturally onto CLAUDE.md. The docs say Claude Code reads and edits files, runs commands, uses persistent CLAUDE.md instructions and auto memory, and asks for permission before modifying files. A practical LLM Wiki arrangement is therefore to store page naming rules, provenance rules, and update procedures in CLAUDE.md, then have the agent edit the relevant Markdown files and optionally run Git commands or lint tools. With Codex, the equivalent control layer is AGENTS.md: Codex reads those files before work, layers guidance from global to repo-local scope, can inspect repositories, edit files, run commands, and exposes action transcripts for review and Git-based rollback. An example such as “ingest raw/meeting-2026-05-07.md, update the decision page, revise index.md, append log.md, and show the diff” is therefore highly plausible, but the exact file conventions are still schema-dependent rather than standardized (inference). (6)
Why now and its limits
Why now
The concept is resonating now because agentic tools have become much better at cross-file reading, editing, command execution, and long-running project guidance. Karpathy’s own public follow-up says the pattern becomes especially interesting once the wiki is large enough—he gives an example of a research wiki with roughly 100 articles and 400,000 words. At the same time, open-source implementations and Hacker News threads appeared within days, which suggests the community sees the pattern as operationally buildable rather than merely rhetorical. (7)
Limits and enterprise challenges
The major criticism is not that the idea is worthless, but that it can be oversold. In the Gist comments, one detailed critique argues that once the wiki exceeds modest size, retrieval, ranking, indexing, reranking, chunking, and access control all come back; another warns that when the same process both reads and writes the knowledge base, “silent corruption” becomes a real risk. Other comments debate whether “wiki” is even the right term for a static or agent-maintained Markdown corpus, though defenders argue the more serious question is not naming but whether the system has citations, provenance, permissions, auditability, and editorial controls. These are community critiques, not Karpathy’s own claims, but they identify the load-bearing risks. (1)
For enterprise use, the mitigation pattern is fairly clear even if no single source yet defines a universal standard. A serious implementation should keep original sources immutable; attach paragraph- or claim-level provenance where possible; stage updates through approval queues rather than writing straight into authoritative pages; maintain append-only operation logs and source hashes; use Git or equivalent rollback; test update quality and contradiction handling; and separate access policy on raw sources from visibility of derived wiki pages. This mitigation bundle is best-practice synthesis rather than a single-source prescription (inference), but it follows directly from Karpathy’s raw/wiki/schema split, his use of log.md and Git, the community implementations’ review and audit features, and the investor-page emphasis on traceability, access rights, conflicting documents, and auditability. (1)
Self-Organizing Wiki as the next evolution
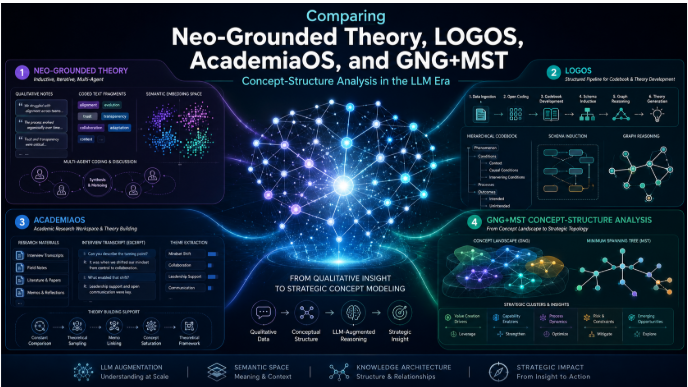
The investor page from explicitly frames a progression: RAG retrieves documents; LLM Wiki compiles knowledge into a persistent wiki; Self-Organizing Wiki organizes that wiki into conceptual maps and associative trails. Its layered model is explicit: Original enterprise sources remain the source of truth, the LLM Wiki layer is AI-generated structured knowledge, the ConceptMiner layer is a self-organizing conceptual map, and the ThinkNavi interface provides exploration, dialogue, synthesis, and decision support. That is an important architectural move because it refuses to treat the AI-generated wiki as the final truth layer in enterprise settings. (2)

ConceptMiner is the most distinctive part of the proposal. According to the investor page, it takes chunks, wiki pages, and generated conceptual descriptions, embeds them, and organizes them with a GNG+MST-based conceptual structure network. The declared outputs are not just nearest-neighbor search results but concept clusters, semantic neighborhoods, bridge concepts, knowledge gaps, duplicated or fragmented concepts, structural changes over time, hidden relationships, and areas where new hypotheses may emerge. It also proposes multiple representational models—Trigger/Situation/Motive, Logical Structure, Implication/Lesson—so that traversal can jump from topical similarity to structural analogy across domains. The page calls the end state “Enterprise Associative Memory.” This is conceptually ambitious, but it remains a public roadmap/positioning document, not an audited technical benchmark. Notably, the same page treats source traceability and audit features as part of the 6–12 month roadmap, so those capabilities should not be assumed to be fully mature today. (2)
Implications for enterprise knowledge management
The most useful enterprise reading is pragmatic. For personal work and slow-moving research, LLM Wiki is already compelling because it converts repeated synthesis into durable pages, reduces repeated rediscovery, and fits naturally with Markdown, links, local Git, and agentic editing. For team use, it becomes attractive when humans can review updates and when work benefits from persistent thematic pages rather than ephemeral chat results. For large enterprise deployments, however, the minimum bar rises sharply: provenance, access control, formal retention and deletion rules, snapshotting, rollback, approval queues, and clear separation between official knowledge and AI-derived interpretation become indispensable. That is exactly why the Mindware page treats the wiki as a middle layer rather than the final source of truth. The cleanest conceptual summary is Karpathy’s compilation layer first, then structural discovery above it, then governed enterprise use around both. (1)
Comparison table
The table below synthesizes Karpathy’s Gist, official documentation for RAG, GraphRAG, NotebookLM, projects in ChatGPT, and the Mindware investor page. The “best-fit scale” and parts of the governance row are analytical synthesis rather than direct one-line claims from any single source. (3)
| Dimension | RAG | LLM Wiki | Self-Organizing Wiki |
|---|---|---|---|
| Primary timing | Query-time retrieval | Ingest-time compilation, query-time reading of compiled pages | Ingest-time compilation plus post-compilation concept modeling |
| Main artifact | Retrieved passages and grounded answer | Persistent Markdown wiki, index, log, derivative answer pages | LLM Wiki plus concept maps, associative trails, exploration interface |
| Source of truth | External knowledge base / original documents | Original sources remain authoritative; wiki is maintained derivative layer | Original enterprise sources explicitly remain the source of truth |
| Traceability | Often strong at passage level if citations are exposed | Varies by implementation; strongest when claim/range provenance is captured | Intended to preserve distinction between sources and AI-generated interpretation |
| Freshness | Usually strong if the index is updated | Depends on re-ingest cadence and maintenance discipline | Depends on source refresh plus concept-layer refresh |
| Scalability | Retrieval infrastructure is mature | Needs search, ranking, and governance once the corpus grows | Adds another abstraction layer, so governance complexity rises further |
| Governance profile | Familiar for enterprise search and grounded QA | Requires added review, audit, rollback, and permission controls | Explicitly designed around layered truth vs interpretation, but current public source is still roadmap-level |
| Best fit | FAQ, grounded QA, rapidly changing corpora | Personal knowledge, research, expert-team synthesis, code/document compilers | Enterprise KM, strategic research, meeting/customer intelligence, associative discovery |
References
Primary and official sources
- [Karpathy’sGitHub Gist「LLM Wiki」](https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f?utm_source=chatgpt.com)
- [Karpathy’sX message「LLM Knowledge Bases」](https://x.com/karpathy/status/2039805659525644595?utm_source=chatgpt.com)
- [Mindware Research Institute page for investors](https://www.mindware-jp.com/en/for-investors/)
- [IBMのRAG review](https://www.ibm.com/docs/en/watsonx/saas?topic=solutions-retrieval-augmented-generation)
- [Google CloudのRAG review](https://cloud.google.com/use-cases/retrieval-augmented-generation)
- [GraphRAG official document](https://microsoft.github.io/graphrag/?utm_source=chatgpt.com)
- [Microsoft Research’s GraphRAG Blog](https://www.microsoft.com/en-us/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/?utm_source=chatgpt.com)
- [NotebookLM official help「Use chat in NotebookLM」](https://support.google.com/notebooklm/answer/16179559?hl=en)
- [ChatGPT Projects official help](https://help.openai.com/en/articles/10169521-projects-in-chatgpt)
- [Obsidian official help「Import Markdown files」](https://obsidian.md/help/import/markdown)
- [Obsidian official help]「Graph view」](https://obsidian.md/help/plugins/graph?utm_source=chatgpt.com)
- [Obsidian official help「Web Clipper」](https://obsidian.md/help/web-clipper?utm_source=chatgpt.com)
- [Claude Code officila document](https://code.claude.com/docs/en/overview?utm_source=chatgpt.com)
- [Codex official document](https://developers.openai.com/codex?utm_source=chatgpt.com)
- [CacheZero repository](https://github.com/swarajbachu/cachezero?utm_source=chatgpt.com)
- [twillmrepository](https://github.com/Jermolene/twillm?utm_source=chatgpt.com)
- [llmwiki repository](https://github.com/lucasastorian/llmwiki?utm_source=chatgpt.com)
Unresolved questions and assumptions
- Direct source gap: Karpathy’s Gist defines the pattern, but it does not standardize parsing, normalization, chunking, source-range citation capture, or merge/conflict logic; those details in this report are therefore marked as inference when derived from community implementations rather than from the Gist itself. (1)
- Direct source gap: No primary source in this review provides a controlled benchmark showing that LLM Wiki broadly outperforms RAG or GraphRAG across accuracy, cost, freshness, and governance. Any claim that LLM Wiki “replaces” RAG would therefore go beyond the evidence currently available. (1)
- Roadmap caveat: The Mindware investor page is the primary public source for Self-Organizing Wiki, but it is clearly an investor/roadmap page. Statements about market direction and planned features can be cited directly; statements about shipped enterprise maturity should be treated cautiously. (2)
- Terminology dispute: The debate over whether a Markdown-based, agent-maintained corpus should be called a “wiki” is real in public discussion, but it is not yet settled by any authoritative technical standard. That naming debate matters mostly for expectation-setting around collaboration, editorial control, and auditability. (1)
Summary
The deepest significance of LLM Wiki is not that it makes retrieval disappear. It is that it treats knowledge work as compilation and maintenance, not just search. Karpathy’s Gist gives a minimal but powerful public pattern for that shift. The investor page from pushes the idea into a more enterprise-oriented direction by separating original sources from AI interpretation and then adding conceptual structure discovery on top. If that roadmap holds, the next frontier in enterprise knowledge systems will not be “better answers” alone, but better knowledge layers: what is original, what is compiled, what is inferred, what is approved, and how all four stay traceable over time.