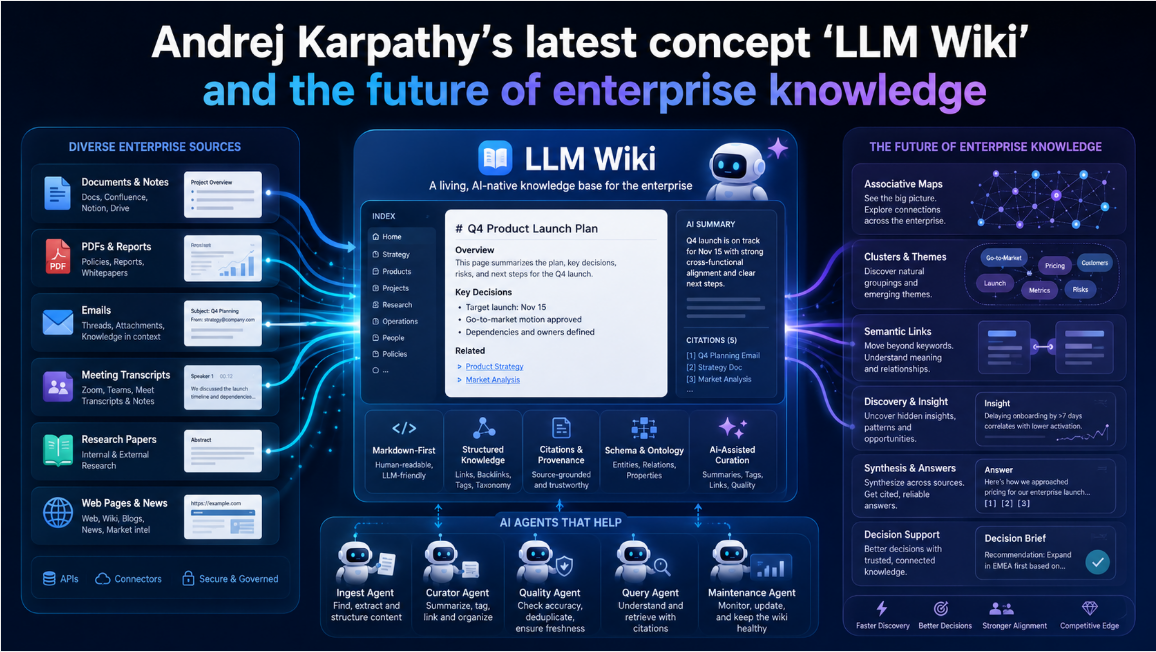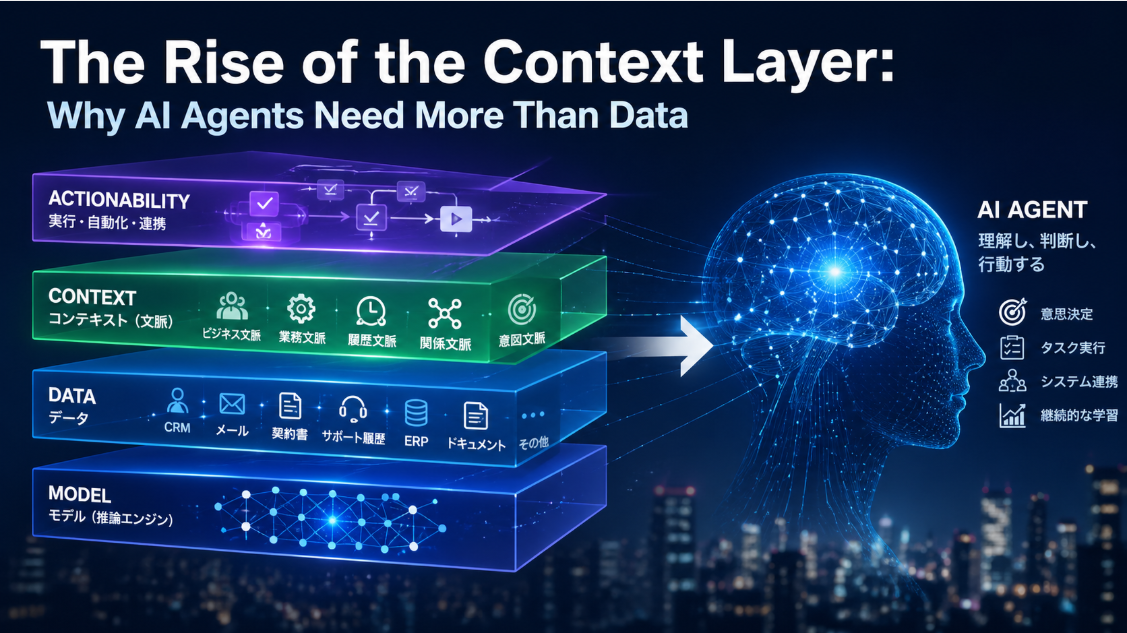
Executive Summary
As of April 2026, “latent space” is no longer a single technical object. Recent surveys now treat it as a broad research landscape rather than a single definition, and the fact that ICLR 2026 hosts a dedicated workshop on latent and implicit thinking is itself evidence that the field has matured into a recognizable program of study. In language-model research especially, the newest surveys define latent space not as one mysterious hidden layer but as a family of hidden-state spaces through which token sequences are mapped, transformed, and projected back into language. (1)
For publication purposes, the cleanest editorial move is to separate at least five senses of the term. First, there are external conceptual or topological maps, such as GNG+MST analyses, which organize semantic neighborhoods after the fact. Second, there are generative-model latent variables, as in VAE-, GAN-, and diffusion-based systems. Third, there are embedding or representation spaces, such as SimCLR, CLIP, and DINOv2, optimized for transfer, retrieval, or alignment rather than reconstruction. Fourth, there are Transformer hidden-state spaces, the internal contextual representations analyzed by probes, lenses, and representational-similarity methods. Fifth, there is operational continuous latent reasoning, where hidden states are reused as a workspace for further computation, as in Coconut, PonderLM, and related work. (2)
That distinction resolves the friction between a GNG+MST white-paper framing and papers such as Training Large Language Models to Reason in a Continuous Latent Space. They are not really disagreeing about one thing. They are using the same phrase for different layers of abstraction. In the GNG+MST sense, latent space is best understood as a researcher-built semantic cartography layered over learned representations. In the Coconut sense, latent space is an internal computational substrate in which the model continues to reason without verbalizing every intermediate step. (2)
The broader literature suggests a simple thesis for a public article: latent space is not one thing, but a family of research programs with different definitions, objectives, geometries, methods, and standards of evidence. The research frontier is now less about proving that latent space matters and more about clarifying which latent space one means, how to evaluate it, and when systems should move between latent and explicit forms. (1)
Title Options and Lead Paragraph
Possible titles for publication:
- Latent Space Is Not One Thing
- From Concept Maps to Continuous Thought
- The Many Lives of Latent Space
- What Researchers Mean by Latent Space Now
- From VAE Codes to Transformer Workspaces
Recommended lead paragraph:
For years, “latent space” sounded like a single idea: the hidden continuous domain behind an AI model’s outputs. In 2026, that definition is no longer adequate. In one research lineage, latent space is a conceptual map built over embeddings, the kind of semantic topology explored by GNG+MST models in ThinkNavi (www.thinknavi.ai). In another, it is the code space of a generator. In another, it is the transferable embedding space of contrastive learning. In another, it is the layer-by-layer hidden-state space of a Transformer. And in the newest reasoning papers, it is not merely a representation at all, but a computational workspace where a model can continue to think without speaking. The most useful way to write about latent space now is in the plural. (2)
Latent Space Now Means Several Different Things
The oldest relevant lineage for your white paper is not the modern LLM reasoning literature at all, but the topology-learning and semantic-mapping tradition. GNG and related topology-representing networks were designed to preserve important neighborhood relations in data. More recent concept-research work and the 2025 Japanese TrendScape paper use this logic to construct networks over language-model representations so that concepts, paths, and local neighborhoods can be explored visually and structurally. In that sense, latent space is an external map of semantic organization rather than the model’s native computational medium. (3)
In the generative-model lineage, latent space usually means a lower-dimensional or structured variable that mediates between observations and generation. VAE introduced the canonical modern formulation; β-VAE and InfoGAN pushed toward disentangled factors; StyleGAN, InterFaceGAN, GANSpace, and SeFa made latent directions directly editable; latent diffusion and diffusion autoencoders turned latent space into a practical substrate for high-quality generation; and recent representation-autoencoder work argues that semantically richer, higher-dimensional latents can outperform older narrow bottlenecks. Here, latent space is primarily about compression, factorization, interpolation, and controllable generation. (4)
In representation learning, the picture changes again. CPC explicitly learns by predicting the future in latent space. SimCLR and DINOv2 optimize latent representations for transfer without requiring labels, and CLIP learns a shared image-text embedding space that is useful for zero-shot classification and retrieval. These spaces are often called latent in practice, but they are not usually latent variables in the VAE sense. Their success criterion is largely task utility, alignment, and transferability, not reconstruction. (5)
In Transformer analysis, latent space now often means the internal hidden-state spaces across layers. That is the dominant sense in the newest language-model surveys. BERT and the subsequent interpretability literature showed that intermediate states can carry rich syntactic and semantic information; structural probes, representation-similarity methods, and lenses turned those states into a research object in their own right. In this regime, latent space is less a compact code than a layerwise trajectory of contextual computation. (6)
The newest regime is operational latent reasoning. Coconut feeds a hidden state back as the next input rather than immediately decoding it into a token. PonderLM introduces continuous “pondering” within a token step. Looped Transformers, CODI, Soft Thinking, LT-Tuning, and planning-style latent CoT methods all explore the same broad question: when should a model compute in hidden space rather than forcing all reasoning through natural-language traces? Here, latent space is neither a post-hoc map nor a static representation. It is a workspace for iterative computation. (7)
| Latent-space sense | Core definition | Main objective | Dominant geometry | Manipulability | Typical methods | Typical evaluation | Representative sources |
|---|---|---|---|---|---|---|---|
| External conceptual or topological map | Post-hoc semantic organization built over embeddings | Exploration, clustering, conceptual path analysis, interpretability | Graph adjacency, neighborhood continuity, path structure | Navigate, cluster, relabel, compare; usually not native generation control | GNG, MST, SOM, TrendScape-style sampling | Neighborhood preservation, path coherence, cluster interpretability, retrieval utility | GNG; TrendScape; concept-research implementations (3) |
| Generative-model latent variables | Learned code mediating reconstruction or sampling | Compression, factor discovery, interpolation, controllable generation | Smooth interpolation, factor axes, semantic directions | High, especially in GAN and diffusion editing pipelines | VAE, β-VAE, InfoGAN, StyleGAN, InterFaceGAN, GANSpace, SeFa, latent diffusion, diffusion autoencoders, RAEs | ELBO, reconstruction, FID, disentanglement metrics, controllability | Canonical generative papers (4) |
| Embedding or representation space | Transfer-oriented continuous representation, often contrastive or aligned across modalities | Retrieval, alignment, zero-shot transfer, downstream performance | Cosine neighborhoods, cluster separation, modality alignment | Moderate; strong for retrieval and steering, weaker for explicit factor edits | CPC, SimCLR, CLIP, DINOv2 | Linear evaluation, zero-shot accuracy, retrieval metrics, robustness | Contrastive and multimodal representation papers (5) |
| Transformer hidden-state space | Internal contextual states across layers and positions | Understanding what the model encodes and how it computes | Layerwise trajectories, residual-space geometry, contextual manifolds | Readout and intervention are possible, but semantic editability is partial and fragile | Probes, structural probes, SVCCA, CKA, Tuned Lens, Patchscopes, Future Lens, Backward Lens | Probe accuracy, representational similarity, decoding fidelity, intervention effects | Hidden-state analysis literature (8) |
| Operational continuous latent reasoning | Hidden states reused as an active reasoning workspace | Efficiency, search, backtracking, internalized CoT, adaptive compute | Recurrent latent trajectories, superposition, planning states | High as a computational substrate, low in direct interpretability | Coconut, PonderLM, Looped Transformers, CODI, Soft Thinking, LT-Tuning, PLaT | Task accuracy vs. token budget, latency, compositionality, stability, shortcut-free reasoning | Recent latent-reasoning papers (7) |
The most important editorial distinction is between post-hoc semantic cartography and native computational substrate. Your GNG+MST framing belongs to the first class. Coconut-style work belongs to the second. Both are valid, but they answer different questions and should not be conflated in a public article. (2)
Comparative Map of Methods, Geometry, and Evaluation
Researchers now evaluate “latent space” with very different instruments depending on which regime they are in. That is one reason the discourse often slides into confusion. FID and ELBO tell you something meaningful about a generative latent, but almost nothing about hidden-state causal use in a Transformer. Probe accuracy and CKA can reveal structure in hidden states, but they do not tell you whether you have a manipulable generative direction. SOCRATES-style compositionality tests matter for latent reasoning, but they are irrelevant to CLIP-style representation alignment. (9)
| Regime | What researchers mostly measure today | Established metrics | What those metrics still miss | Key sources |
|---|---|---|---|---|
| External conceptual maps | Whether semantic neighborhoods and paths are intelligible and useful | Neighborhood preservation, cluster coherence, retrieval quality, qualitative map reading | Whether the map reflects causal model use rather than a convenient overlay | (2) |
| Generative latent variables | Whether latent codes reconstruct well, sample well, and expose editable factors | ELBO, reconstruction error, FID, DCI, FactorVAE-style disentanglement scores | Ground-truth-free semantic structure; causal interpretability beyond editing success | (4) |
| Embedding spaces | Whether features transfer, retrieve, and align domains or modalities | Linear evaluation, zero-shot transfer, retrieval recall, robustness benchmarks | Internal causal structure and whether geometry corresponds to human concepts | (10) |
| Hidden-state spaces | Whether linguistic or semantic information can be decoded from intermediate states | Probe accuracy, structural probes, CKA, SVCCA, lens fidelity | Whether decoded features are actually used by the model during inference | (8) |
| Operational latent reasoning | Whether hidden-space computation improves reasoning efficiency or search | Accuracy per token, latency, compositionality, shortcut-free multi-hop reasoning, robustness | Faithfulness, controllable stopping, certainty calibration, transparent causal traces | (7) |

The flowchart is not a claim that one line simply replaced another. It shows convergence. Topology learning fed semantic mapping, generative modeling built manipulable code spaces, representation learning normalized the language of embeddings, interpretability turned hidden states into objects of study, and latent-reasoning papers then treated those states as a workspace for real computation. The recent surveys and workshop mark the point where these lines begin to be discussed as a common field. (3)
What Current Evidence Shows
The empirical record is strongest in generative vision. InterFaceGAN, GANSpace, and SeFa all show that well-trained GANs can contain semantically meaningful directions for editing pose, age, expression, layout, and similar attributes. Latent diffusion moved image synthesis into a compressed latent substrate, and diffusion autoencoders split semantics from stochastic detail in a way that improved both reconstruction and manipulation. The newest representation-autoencoder papers push this further by arguing that diffusion systems benefit from richer semantic latents, not merely smaller ones. (11)
Representation spaces tell a different story. CPC, SimCLR, CLIP, and DINOv2 demonstrate that a continuous space can be extraordinarily useful even when it is not explicitly disentangled or reconstructive. What matters there is whether the space supports transfer, retrieval, and alignment. That is why “latent space” in this regime often means something more like task-optimized geometry than hidden causal factors. (5)
For Transformer hidden states, the literature now supports two claims at once. First, the states are genuinely structured: BERT-style models encode rich linguistic information, structural probes can recover tree distance and depth after linear transformation, and newer concept-geometry work finds evidence that categorical and hierarchical concepts occupy systematic regions of representation space. Second, decoding information from a state is not the same as proving that the model relies on that information. That is why the field has moved from probes alone toward CKA, Tuned Lens, Patchscopes, Future Lens, and backward-pass methods. (8)
The latent-reasoning evidence is promising but mixed. Coconut shows that continuous hidden-state reasoning can outperform explicit chain-of-thought on tasks that require search and backtracking, while consuming fewer reasoning tokens. PonderLM and Looped Transformers suggest that additional hidden-space computation can be built directly into pretraining or effective depth. CODI, Soft Thinking, LT-Tuning, and planning-style latent CoT methods show that the design space is expanding rapidly. But shortcut-free evaluation on SOCRATES and the 2026 “Capabilities and Fundamental Limits” paper both suggest that latent reasoning remains brittle: it is better at exploration and superposition than at exact, compositional execution. (7)
Multilingual and culturally specific findings add another corrective. The 2025 paper Do Multilingual LLMs Think In English? argues that many multilingual systems route key decisions through an English-like internal representation space. Japanese work complicates the picture further: one 2026 study finds “latent kanjification” in Japanese-centered models, where intermediate layers transiently favor kanji-rich representations even when the final answer is in hiragana; another 2025 study finds that Japanese historical periods can be positioned in a monotonic latent order even when directional axes are not cleanly aligned; and a 2026 study questions whether latent-language consistency is even necessary for downstream performance. These results make it harder to talk about latent space as a culturally neutral universal semantic medium. (12)
What Remains Unresolved
The first unresolved problem is evaluation fragmentation. The generative literature has DCI, FactorVAE-style scores, reconstruction, and FID. The hidden-state literature has probe accuracy, structural probes, CKA, SVCCA, and lens-based decoding. The latent-reasoning literature has token-efficiency curves, shortcut-free multi-hop benchmarks, and increasingly ad hoc measures of latent consistency or planning depth. None of these forms a unified framework across regimes. The field still lacks a way to compare geometry, semantics, causal use, and downstream utility in a single vocabulary. (9)
The second unresolved problem is causal grounding. The broad consensus after years of probe work is that recoverability is not the same thing as functional necessity. Attention Is Not Explanation remains a landmark warning, and later methods such as Patchscopes, Future Lens, Backward Lens, and Back Attention are all attempts to move from descriptive decoding toward causal diagnosis. But the field still has more ways to inspect hidden states than to prove how they are being used. (13)
The third unresolved problem is compositionality. SOCRATES shows that latent multi-hop reasoning exists, but only unevenly, and that explicit chain-of-thought still outperforms latent reasoning on truly shortcut-free composition in many settings. The 2026 theoretical work on latent CoT sharpens that point by framing an exploration-execution tradeoff: continuous superposition helps preserve multiple possibilities, but the same openness can blur exact symbolic commitment. PLaT’s diversity-vs.-accuracy tradeoff points in the same direction. (14)
The fourth unresolved problem is multilingual and cultural specificity. The internal geometry of LLMs is shaped by training distribution, tokenization, script, and linguistic hierarchy. English-like latent routing in multilingual models, latent kanjification in Japanese-centered models, and distinct behavior on Japanese temporal structure all suggest that latent spaces are historically and linguistically contingent. Any public article that treats latent space as a universal meaning reservoir should therefore be more cautious than the field often is. (15)
The strongest near-term design prospect is therefore hybrid architecture. Several 2026 papers now move explicitly in that direction: systems that learn when to replace low-entropy reasoning steps with latent embeddings, frameworks that dynamically switch between latent and explicit modes, and retrievers that internalize explicit reasoning trajectories into efficient latent paths. The likely future is not latent-only reasoning, but architectures that can translate back and forth between latent workspaces and explicit language when the task demands it.
Publication Draft for aicritique.org
Recommended title: Latent Space Is Not One Thing
Deck: The phrase that once described a hidden code behind AI outputs now names at least five different research programs, from conceptual maps and generative latents to Transformer workspaces and continuous reasoning.
The phrase that outgrew its original meaning
For years, “latent space” was useful because it seemed simple. It named the hidden continuous domain behind an AI model’s outputs: not the visible tokens or pixels, but the underlying space in which structure was encoded. That older intuition still matters. But in 2026 it is no longer enough. Recent surveys now describe latent space not as one stable concept but as a growing technical landscape, and the emergence of a dedicated ICLR workshop on latent and implicit thinking shows that the term has become central to the way researchers talk about internal computation in modern models. (1)
The problem is not that researchers are using the phrase incorrectly. The problem is that they are using it for different things. In one line of work, latent space is a map. In another, it is a code. In another, it is a transfer-optimized embedding space. In another, it is the family of hidden states inside a Transformer. And in the newest reasoning papers, it is something even stronger: a workspace where the model continues to compute without verbalizing every intermediate step. (2)
That distinction matters because it clarifies an apparent contradiction in current AI criticism and AI theory. If one writes about latent space as the part of meaning space humans have not yet fully verbalized, that sounds different from papers that define it more concretely as a Transformer’s internal hidden-state trajectory. But these are not necessarily competing definitions. They sit at different levels. One treats latent space as an externally constructed semantic topology. The other treats it as the model’s own internal computational medium. (2)
Five programs hiding behind one phrase
The first sense of latent space is the one most relevant to GNG+MST-style conceptual investigation. Here the latent space is a conceptual or topological map built over learned representations. The goal is not to train a model to generate with that space directly, but to organize semantic neighborhoods so that paths, clusters, and local relations can be explored. The original GNG literature comes from topology learning, and newer work such as TrendScape applies related thinking to language-model concept exploration. This is less like opening the model’s skull and more like drawing a semantic atlas from the representations it already produces. (3)
The second sense is the classic generative-model latent variable. This is the lineage of VAE, β-VAE, InfoGAN, StyleGAN, InterFaceGAN, GANSpace, SeFa, latent diffusion, and diffusion autoencoders. In this world, latent space is usually a code that mediates reconstruction or generation. Researchers care about whether it supports interpolation, whether individual directions correspond to meaningful factors, whether it can be edited, and whether it balances compression with semantic richness. Recent diffusion work suggests that the old ideal of a narrow bottleneck may be giving way to richer semantic latents rather than smaller ones. (4)
The third sense is the embedding or representation space of self-supervised and multimodal learning. CPC, SimCLR, CLIP, and DINOv2 all live here. These systems are often described as learning latent representations, but what matters most is not reconstructing an input from a hidden code. What matters is whether the space transfers, aligns, and separates useful structure across tasks and modalities. In this regime, latent space is practical geometry: a good place to retrieve neighbors, transfer features, or align images with text. (5)
The fourth sense is the hidden-state space inside Transformers. This is now the dominant definition in recent language-model surveys. BERT and the interpretability literature taught researchers to treat intermediate states as serious objects of study. Probes, structural probes, CKA, SVCCA, Tuned Lens, Patchscopes, Future Lens, and newer gradient-based methods all ask versions of the same question: what is encoded in those states, how is it geometrically organized, and how does it evolve layer by layer? This latent space is not primarily a compressed code. It is the running internal state of the computation. (6)
The fifth and newest sense is operational latent reasoning. Coconut made the turning point visible by feeding a hidden state back as the next reasoning input instead of immediately decoding a token. PonderLM, Looped Transformers, CODI, Soft Thinking, LT-Tuning, and planning-style latent chain-of-thought papers show how quickly that idea has expanded. Here, latent space is not just where information resides. It is where thinking happens. (7)
The hidden-state turn
The reason current debates feel so different from older ones is that hidden states are no longer being treated as passive storage. Earlier work mostly asked what could be decoded from them. Later work asked whether syntactic or semantic structure could be geometrically recovered from them. The newest work asks whether they can serve as an actual medium for iterative reasoning, search, and planning. That change turns latent space from an interpretability object into a computational one. (8)
This is where the phrase becomes genuinely consequential. If the model’s real reasoning is happening in hidden-state trajectories rather than in the natural-language chain-of-thought it later emits, then public debates about transparency, traceability, and explanation need to be updated. The visible reasoning trace may be informative, but it may not be the whole reasoning process and may not even be the primary one. That is why the latent-reasoning literature keeps returning to tradeoffs between efficiency, faithfulness, and interpretability. (16)
What experiments really show
The evidence is strongest where the field has mature manipulation tools. In vision, GAN and diffusion work has repeatedly shown that latent directions can be used to edit semantic properties in stable and useful ways. That makes the idea of latent space intuitive: it looks like a place where meaning really has direction. (11)
In language models, the picture is more complex. Hidden-state analysis gives real evidence of structure: structural probes recover syntactic relations; concept-geometry work finds systematic organization for categorical and hierarchical concepts; and behavior-vs.-geometry studies show that some aspects of hidden semantic organization can be recovered from external behavior alone. But it remains dangerous to jump from “decodable” to “causal.” That caution is now one of the field’s deepest norms. (8)
Operational latent reasoning sharpens both the promise and the limit. Coconut and related work suggest that hidden-space computation can preserve multiple possible next steps and help with search-heavy reasoning. But shortcut-free benchmarks such as SOCRATES, along with 2026 theoretical work on latent chain-of-thought, show that latent reasoning still struggles when exact compositional execution matters. The result is a striking asymmetry: latent reasoning is often good at exploration, but still unreliable as a full symbolic substitute. (7)
Multilingual evidence raises a further challenge. If multilingual LLMs often route key decisions through an English-like internal space, and if Japanese-centered models exhibit emergent internal kanjification even when outputting hiragana, then latent space is not simply a universal semantic ether. It is shaped by corpus balance, script, tokenization, and cultural history. That makes the politics of latent space harder and more interesting than the smooth universalist metaphors often suggest. (12)
Why the next phase will be hybrid
The most plausible future is not a world in which explicit reasoning disappears. It is a world in which models learn when to move into latent computation and when to come back into language. Several 2026 papers are already heading in that direction, using reinforcement learning, curriculum strategies, or explicit-latent alignment to decide where continuous tokens should replace verbalized steps and where language remains necessary. (15)
That is the most useful conclusion for a public audience. “Latent space” should no longer be treated as a vague synonym for hidden meaning. It should be treated as a family of technical regimes. Some are maps. Some are codes. Some are embedding geometries. Some are internal state trajectories. Some are computational workspaces. Saying which one you mean is no longer a matter of stylistic precision. It is the only way to make the term analytically serious. (1)
A short conclusion for publication:
The real story of latent space is not that AI has discovered one hidden world beneath language. It is that modern AI research has built several different hidden worlds and is only now learning to distinguish them. GNG+MST conceptual maps, generative latent variables, contrastive embedding spaces, Transformer hidden states, and continuous latent reasoning all belong to the same conversation, but they are not interchangeable. The next phase of the field will be defined by clearer taxonomy, stronger causal evaluation, and hybrid systems that know when to think silently and when to speak. (2)
References
- Topology and conceptual mapping: A Growing Neural Gas Network Learns Topologies; Topology Representing Networks; TrendScape 1.0: Concept Exploration on the Latent Space of Language Models; Mindware’s concept-research pages on GNG+MST semantic modeling. (3)
- Generative-model latents: Auto-Encoding Variational Bayes; β-VAE; InfoGAN; A Style-Based Generator Architecture for Generative Adversarial Networks; InterFaceGAN; GANSpace; Closed-Form Factorization of Latent Semantics in GANs; High-Resolution Image Synthesis with Latent Diffusion Models; Diffusion Autoencoders; Diffusion Transformers with Representation Autoencoders. (4)
- Representation spaces: Representation Learning with Contrastive Predictive Coding; A Simple Framework for Contrastive Learning of Visual Representations; Learning Transferable Visual Models From Natural Language Supervision; DINOv2. (5)
- Transformer hidden-state analysis: BERT; A Structural Probe for Finding Syntax in Word Representations; What Does BERT Look at?; A Primer in BERTology; Probing Classifiers; Attention Is Not Explanation; SVCCA; Similarity of Neural Network Representations Revisited; Eliciting Latent Predictions from Transformers with the Tuned Lens; Patchscopes; Future Lens; Backward Lens; The Geometry of Categorical and Hierarchical Concepts in Large Language Models. (6)
- Latent reasoning and continuous hidden-space computation: Training Large Language Models to Reason in a Continuous Latent Space; Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?; Back Attention; PonderLM; Reasoning with Latent Thoughts; CODI; Soft Thinking; Latent Thoughts Tuning; Latent Chain-of-Thought as Planning; Capabilities and Fundamental Limits of Latent Chain-of-Thought; Learning to Reason over Continuous Tokens with Reinforcement Learning; Efficient Post-Training Refinement of Latent Reasoning in Large Language Models. (7)
- Multilingual and Japanese studies: Do Multilingual LLMs Think In English?; How Do Japanese LMs Encode Temporal Structure?; Which Script Does a Japanese LLM Pass Through Internally?; Should a Large Language Model’s Latent Language Be Consistent? (12)
- Recent surveys and field consolidation: The Latent Space: Foundation, Evolution, Mechanism, Ability, and Outlook; A Survey on Latent Reasoning; Implicit Reasoning in Large Language Models; the ICLR 2026 workshop on latent and implicit thinking. (1)