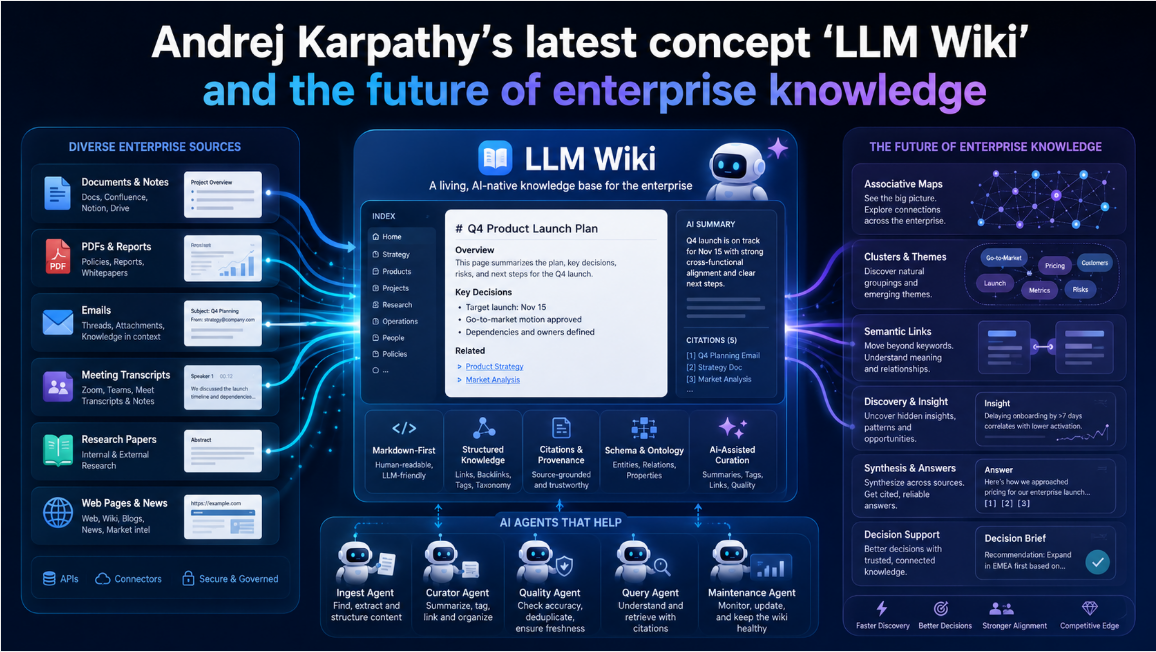
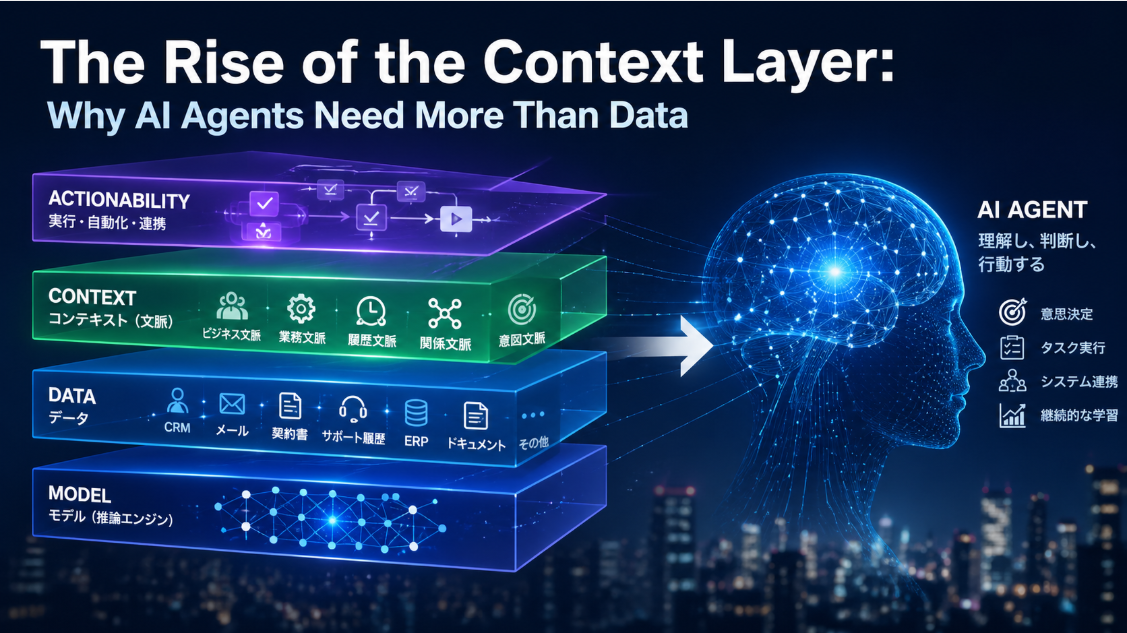
Basic Concepts and Historical Background
Definition of Grokking: Grokking refers to a surprising phenomenon of delayed generalization in neural network training. A model will perfectly fit the training data (near-100% training accuracy) yet remain at chance-level on the test set for an extended period. Then, after many more training iterations, the test performance suddenly jumps to near-perfect (sometimes almost overnight) even though training loss had long convergedar5iv.labs.arxiv.orgar5iv.labs.arxiv.org. This was first clearly documented by Power et al. (2022) on small algorithmic tasks (e.g. modular arithmetic). They showed that with small synthetic datasets (like learning modular addition or multiplication tables), neural networks can memorize the training set quickly but only “grok” the underlying pattern much later, exhibiting an abrupt transition from overfitting to generalizationar5iv.labs.arxiv.org. Crucially, this jump occurs well past the point of overfitting – e.g. thousands of optimization steps after training accuracy is 100%ar5iv.labs.arxiv.orgar5iv.labs.arxiv.org. Grokking is thus characterized by extreme training time disparity: training loss reaches near-zero early, but validation loss/accuracy only improves dramatically after a long plateauar5iv.labs.arxiv.orgar5iv.labs.arxiv.org.
Initial Discovery (Power et al., 2022): In their seminal work, Power et al. trained small transformers on binary operation tables (e.g. modular addition or division). They observed that for sufficiently small datasets, validation accuracy remained at random chance even after training accuracy was perfect, then spiked to 100% after extended trainingar5iv.labs.arxiv.orgar5iv.labs.arxiv.org. They coined this late generalization “grokking.” They also found that smaller datasets require dramatically more training steps to grok (sometimes a 1% decrease in data required ~50% more steps to generalize)ar5iv.labs.arxiv.org. Notably, regularization (especially weight decay) was found to accelerate grokkingar5iv.labs.arxiv.org – with weight decay, the time to generalize was reducedar5iv.labs.arxiv.org. Power et al.’s results established grokking as a real phenomenon and suggested that these toy tasks are a “fertile ground” for studying generalization beyond memorizationar5iv.labs.arxiv.org. The discovery raised fundamental questions: Why can a network eventually generalize perfectly without new data or changes in training loss? What evolves internally during the long plateau? These questions spurred numerous follow-up studies.
Key Characteristics: To summarize, the hallmark features of grokking are: (1) Delayed generalization: a long period of overfitting (training performance ≫ test performance) followed by a sudden test performance jumpar5iv.labs.arxiv.org. (2) Sharp phase transition: the improvement in validation accuracy is rapid once it begins (resembling a phase change rather than gradual improvement)ar5iv.labs.arxiv.orgar5iv.labs.arxiv.org. (3) Small data regime: grokking is easiest to observe on relatively small or algorithmic datasets where the network can eventually learn the structure instead of just brute-force memorizingar5iv.labs.arxiv.orgar5iv.labs.arxiv.org. (4) Dependence on hyperparameters: factors like weight decay, learning rate, and model capacity influence whether and when grokking occursar5iv.labs.arxiv.orgar5iv.labs.arxiv.org. For example, high weight decay tends to encourage the model to eventually find a simpler, generalizing solution rather than sticking to a memorizing solutionar5iv.labs.arxiv.org. Grokking was initially documented in small transformers on tasks like modular arithmeticar5iv.labs.arxiv.org, but subsequent work (discussed below) has found analogous behavior in other architectures and even non-neural models, indicating it taps into a general phenomenon about learning dynamics.
Theoretical Explanations and Mechanistic Models
Researchers have proposed several theoretical frameworks to explain why grokking happens. These include views based on training dynamics regimes, representation learning “phases,” mechanistic circuit formation, and statistical distribution shifts. We outline the major explanations:
(a) Lazy-to-Rich Training Dynamics (Kumar et al., 2024): Kumar and colleagues interpret grokking as a consequence of a neural network transitioning from a “lazy” learning regime to a “rich” feature-learning regimeopenreview.netopenreview.net. In the lazy regime, the network’s parameters change only minimally (akin to a kernel or linear model), so the network initially fits the training data using its fixed initial features (essentially performing something like kernel regression)openreview.netopenreview.net. This can drive training loss down (memorizing the training set) but doesn’t generalize if the initial random features aren’t aligned with the true patternopenreview.netopenreview.net. After this, a late-phase transition happens: the network eventually leaves the lazy regime and begins genuine feature learning (the “rich” regime)openreview.netopenreview.net. At this point it discovers new representations that capture the underlying structure, leading to a sudden generalization jump. Kumar et al. demonstrated this mechanism in a simple two-layer network on a polynomial task that groks even without regularizationarxiv.orgarxiv.org. They identified conditions for grokking: (1) Misaligned initial kernel: the top eigenfunctions of the Neural Tangent Kernel are not aligned with the target function, so initial learning struggles to generalizeopenreview.netopenreview.net. (2) Intermediate dataset size: enough data that generalization is eventually possible, but not so much that test performance tracks training performance from the startopenreview.netopenreview.net. (3) Small initial step size (or network scaling): ensuring training starts in the lazy/linear regime rather than immediately learning featuresopenreview.net. Under these conditions, the network first fits training data like a linear model (lazy phase), then later switches to learning new features that solve the task (rich phase), which coincides with grokkingopenreview.netopenreview.net. This theory connects grokking to classical ideas of neural tangent kernels vs. feature learning. Indeed, they provided evidence in settings like MNIST and simple transformers that delaying feature learning can induce grokkingopenreview.netopenreview.net. In short, grokking = the moment the network stops being a mere “lazy” interpolator and actually learns the true features, causing test accuracy to leapopenreview.netopenreview.net.
(b) Effective Theory and the “Goldilocks Zone” (Liu et al., 2022): Another perspective comes from Liu et al., who developed an effective theory of representation learning to map out different “phases” of trainingpapers.neurips.ccpapers.neurips.cc. They ran extensive experiments on algorithmic tasks and identified four regimes: confusion, memorization, grokking, and comprehensionpapers.neurips.cc. – Confusion means the model fails to even memorize (training loss high). Memorization means it can fit training data but not generalize. Comprehension means it generalizes quickly (no long delay). Grokking is the in-between case of delayed generalizationpapers.neurips.ccpapers.neurips.cc. Crucially, they found representation learning only happens in a “Goldilocks zone” between pure memorization and pure confusionpapers.neurips.ccpapers.neurips.cc. In this zone (which includes the comprehension and grokking phases), the model learns structured internal representations that enable generalizationpapers.neurips.ccpapers.neurips.cc. If hyperparameters are tuned for too-rapid learning or too slow, the model either trivially memorizes or never learns anything useful (confusion). But just-right settings (not too much data or too high learning rate) force the model to “struggle” and in doing so, discover structurepapers.neurips.ccpapers.neurips.cc. They observed that in transformers, the grokking phase sits closer to memorization on this spectrum, hence generalization is delayedpapers.neurips.cc. Intuitively, grokking is an “undesirable” phase caused by slightly improper hyperparameters that slow representation learningpapers.neurips.cc. By charting phase diagrams of training dynamics (varying e.g. learning rate for embeddings vs. decoder, or weight decay), they showed one can see regions corresponding to each phasepapers.neurips.ccpapers.neurips.cc. Notably, grokking appears sandwiched between the fast-generalizing comprehension phase and the pure memorization phasepapers.neurips.cc. If one tunes hyperparameters toward comprehension (e.g. a somewhat faster or more flexible representation learning), the model can “de-delay” generalization and avoid the grokking plateaupapers.neurips.cc. This framing suggests grokking is not a mysterious anomaly but a point on a continuum of learning behaviors, explainable by the competition between learning representations vs. overfitting weights. They even likened the effect to “intelligence from starvation” in evolution – i.e., resource limitations (small data, weight decay) force the network to find a more efficient solution once pure memorization failspapers.neurips.cc. Overall, Liu et al. provided an intuitive phase diagram: grokking happens when a network eventually exits a near-memorization phase to find structure, and careful tuning can eliminate the delaypapers.neurips.ccpapers.neurips.cc.
(c) Phase Transitions & Mechanistic Interpretability (Nanda et al., 2023): Some researchers approached grokking by reverse-engineering the network’s internal mechanism on a grokking task. Nanda et al. performed a detailed mechanistic interpretability analysis of a small transformer trained on modular addition, to see what changes inside the model during grokkingarxiv.org. They found that the model actually learns a sensible algorithm: it represents numbers in a Fourier basis and performs addition via rotations on the circle (a known algorithm for modular addition)arxiv.org. Importantly, they identified three continuous “phases” in training: (1) Memorization phase: the network first stores some training mappings (e.g. lookup table behavior) to drive training loss down. (2) Circuit formation phase: the network gradually builds up the correct algorithmic circuit (sine/cosine representations for numbers, etc.) while still mostly memorizingarxiv.org. (3) Cleanup phase: the network removes or downweights the memorization-based components and relies on the general algorithm, which suddenly boosts test accuracyarxiv.org. In this view, grokking is not actually a “magic” sudden insight but the result of a gradual improvement in the learned representations/circuits that isn’t reflected in test performance until a tipping pointarxiv.org. Their progress measures showed that the “general” circuit’s strength grows continuously and the “memorization” circuits decay, and the test accuracy jump happens when the general circuit’s signal dominatesarxiv.org. Thus, what looks like a phase transition from the outside is underpinned by continuous changes internally. They conclude that grokking = the emergent result of two competing solution circuits – one brute-force memorizing, one generalizing – where the generalizing circuit eventually wins outarxiv.org. This aligns with earlier informal conjectures (e.g. by Millidge 2022, Shah 2021) that grokking may involve the network first finding a shortcut (memorization), then later discovering the true pattern and switching overpapers.neurips.cc. Mechanistic studies by Nanda et al. and others also highlight the role of weight decay: weight decay preferentially suppresses complex memorizing solutions, effectively encouraging the network to find the more structured algorithm soonerar5iv.labs.arxiv.org. In summary, a mechanistic view treats grokking as a competitive phase transition between different “circuits” in the model – when the simplistic memorization falls away and the elegant general solution crystallizes, we see a sudden performance jumparxiv.org.
(d) Statistical and Distribution-Shift Explanations (Carvalho et al., 2025): A recent line of work frames grokking as a statistical phenomenon related to distribution shift. Carvalho et al. argue that a key factor behind grokking is a mismatch between the training distribution and the test distributionarxiv.orgarxiv.org. In their view, small or biased training sets create implicit distribution shifts that the model must eventually recognize. They formalize “late generalization” and demonstrate grokking on carefully constructed synthetic datasets that manipulate class/subclass distributionsarxiv.orgarxiv.org. For example, they create a dataset where each class has two subclasses. If one subclass is sparsely sampled in training, the model initially overfits (focusing on the dominant subclass), but much later it learns to leverage relationships between subclasses, allowing generalization to the sparse subclassarxiv.orgarxiv.org. This manifests as grokking. By controlling sampling imbalance, they could induce or prevent grokking at will (e.g. removing a subclass entirely prevented late generalization, while weakly sampling it caused grokking)arxiv.orgarxiv.org. They conclude that data sparsity alone isn’t the direct cause – rather, data sparsity causes an implicit shift that the model only overcomes after learning higher-level relationsarxiv.orgarxiv.org. Interestingly, they show grokking can occur even with dense data and minimal hyper-parameter tuning, contrary to early beliefs that you needed extremely tiny data and heavy regularizationarxiv.org. They also extended experiments to a real-world scenario (inducing distribution shift on MNIST digits via clustering distortions) and observed delayed generalization there as wellarxiv.orgarxiv.org. This statistical view connects grokking with phenomena like domain adaptation: the training set is not fully representative, and only after memorizing does the model find a more general decision boundary that works for the broader distributionarxiv.orgarxiv.org. One practical outcome they stress is the need for better early-stopping or progress metrics – since traditional validation loss might be flat during the grokking plateau, one might prematurely stop trainingarxiv.orgarxiv.org. Their work “paves the way for developing better stopping criteria” by understanding how distribution structure cues late generalizationarxiv.org. In essence, the Carvalho et al. explanation is: grokking happens when the training data is just sufficient to eventually infer a general rule, but not initially sufficient to show that generalization on the test distribution is possible – the model initially fits idiosyncrasies, then slowly figures out the underlying pattern connecting train and test distributionsarxiv.orgarxiv.org.
Each of these frameworks sheds light on grokking from different angles (dynamics, representations, circuits, data distribution). They aren’t mutually exclusive; indeed, there’s a sense in which “circuits competition”, “lazy-to-rich transition”, and “distribution shift recognition” might be describing the same core process at different levels. The next framework attempts to unify some of these ideas.
(e) Unified “Circuits Competition” Framework (Huang et al., 2024): Huang et al. propose a unifying view connecting grokking with double descent (the puzzling re-improvement of test error when model size grows) and emergent abilities in LLMsarxiv.orgarxiv.org. They build on the idea of memorization vs. generalization circuits competing inside the modelarxiv.orgarxiv.org. This perspective was initially used for grokking (as discussed by Nanda et al.), but Huang et al. extend it across different scales of model size and data sizearxiv.orgarxiv.org. Their framework outlines four training dynamics regimes depending on model capacity and data: for instance, (1) small model + little data = can’t even memorize (underfitting), (2) large model + little data = memorization (overfitting), (3) intermediate model/data = grokking (late generalization), (4) large model + ample data = immediate generalization (comprehension)arxiv.orgarxiv.org. This mirrors the phases discussed by Liu et al., but explicitly ties them to model size and the classic double-descent curve. Using this framework, they reinterpret double descent: as model size increases, initially a model memorizes (test error high), but beyond a critical size it can implement generalizing circuits, causing test error to drop again (second descent)arxiv.orgarxiv.org. They made two predictions about when double descent occurs based on this circuits competition, and verified them experimentallyarxiv.orgarxiv.org (for example, predicting the model size at which memorization gives way to generalization given a fixed data size). Furthermore, they extended the idea to multi-task learning and emergent abilities. By treating an “algorithmic” task as an emergent ability (e.g. a task that only larger models learn, analogous to tasks that only “emerge” in very large LLMs), they show that the same framework predicts when a task will suddenly be learned (emerge) as data or model scale increasesarxiv.org. In other words, an emergent ability can be seen as grokking in the context of many tasks: smaller models effectively memorize training tasks without discovering the algorithm for the “emergent” task, until a certain scale where the circuit for that task can form and win outarxiv.org. This offers a novel theoretical lens on why large language models suddenly acquire new skills at scale – it’s the outcome of internal competition between specialized circuits, analogous to grokking dynamics. Overall, Huang et al.’s contribution is a conceptual synthesis: grokking, double descent, and emergent capabilities are all manifestations of the same underlying dynamic of memorization vs. generalization circuits, playing out over different axes (time, model size, or task complexity)arxiv.orgarxiv.org. This unified view helps tie the grokking literature into the broader context of generalization phenomena in deep learning.
Applicability and Generalization Across Model Types
Initially, grokking was studied in small transformers on synthetic tasks. A natural question is: does grokking occur in other models, or is it unique to deep neural networks (and to those specific tasks)? Recent research indicates grokking is more general – it appears in various model families and deeper networks, though sometimes in modified forms.
Grokking in Non-Neural Models (Miller et al., 2023): Strikingly, Miller et al. showed that grokking is not exclusive to neural nets – they observed analogous delayed generalization in models like Gaussian Processes (GPs), simple linear regression, and Bayesian neural networksarxiv.orgarxiv.org. In their study, even a Gaussian process classifier trained on a small algorithmic dataset displayed a grokking-like jump in test performance after more data was effectively consideredarxiv.org. Likewise, linear regression on a certain structured task showed a form of late generalizationarxiv.org. This is surprising because these models don’t undergo iterative “feature learning” in the neural sense. Miller et al. argue the common factor is that these learning methods can be implicitly guided by a notion of solution complexity vs. error trade-offarxiv.org. For example, in GP regression with a certain kernel, the function that fits the training data initially might be very wiggly (memorizing), but as the GP posterior updates (or as hyperparameters favor smoother functions), a simpler generalizing function can eventually dominate – analogous to a late shift to a low-complexity solutionarxiv.org. They even devised a way to induce grokking behavior in algorithmic tasks by adding spurious input dimensions: extra random features that the model can memorize initially, forcing a delay until it learns to ignore them and focus on real featuresarxiv.org. The key takeaway is any learning system that balances model complexity and fit could exhibit grokkingarxiv.org. Grokking is “not restricted to settings considered in current theoretical and empirical studies” – it may arise “in any model where solution search is guided by complexity and error”arxiv.org. In simpler terms, if a learning algorithm can first find a more complex solution that fits the data and only later shift to a simpler, generalizing solution, it can grok. This finding broadens the scope: delayed generalization is not a quirk of backpropagation or transformers, but a potential phenomenon in general learning dynamics, including Bayesian paradigms. It invites theoretical analysis of, say, double descent in kernel methods and how that might relate to grokking. (Indeed, double descent in linear models could be seen as a cousin of grokking, where varying model complexity yields non-monotonic generalization.)
Deep Neural Networks and Multi-Stage Generalization (Fan et al., 2024): Earlier grokking studies mostly used shallow networks (e.g. a 1-layer transformer). Fan et al. asked: what happens in deeper neural networks? They trained deeper MLPs (up to 12 layers) on algorithmic tasks and found that deeper networks not only grok, but can exhibit multiple grokking stagesarxiv.orgarxiv.org. Specifically, a 12-layer network sometimes showed two distinct jumps in test accuracy: an initial delayed jump, then after further training, a second surge in performancearxiv.org. This “multi-stage generalization” was rarely seen in shallow modelsarxiv.org. It suggests that deeper models might learn complex tasks in a hierarchical fashion – e.g. first grok some simpler aspect, then later grok a finer aspect. Correspondingly, Fan et al. measured the internal feature rank (roughly, the dimensionality of the learned representations) over trainingarxiv.org. They observed that as grokking occurs, the feature rank of intermediate layers drops, indicating the network’s representations become more compressed and structuredarxiv.org. Intriguingly, the feature rank trajectory often showed a double-descent shape: it would decrease, then increase, then decrease again, aligning with the two surges in accuracyarxiv.org. In other words, when test accuracy made a second leap, it coincided with another drop in feature rank complexity. These findings hint that internal representation compression is a signature of generalization – the network throws away redundant/memorized information and distills a more low-dimensional concept, which yields better generalizationarxiv.org. They even suggest that feature rank might predict grokking better than weight norm or other metricsarxiv.org. Practically, one could monitor feature rank during training as an unsupervised indicator of an impending generalization jumparxiv.org. Fan et al.’s work expands grokking research to deeper architectures, showing that depth can increase the propensity to grok (they found deep nets were more susceptible to grokking than shallow ones)arxiv.org. It also reinforces connections between grokking and double descent: the double descent in feature complexity mirrors a kind of double descent in performancearxiv.org. In summary, deep networks can grok in potentially multiple phases, and studying their layerwise representations (like rank) can reveal how generalization emerges internally across training stagesarxiv.org.
Unified Perspectives: Grokking, Double Descent, Emergence (Huang et al., 2024): As mentioned earlier, Huang et al. provide a framework that unifies these phenomena by focusing on circuits competition across scalesarxiv.orgarxiv.org. In the context of different model types: double descent has been observed in linear models and random forests, and emergent abilities are discussed for LLMs – by showing these can all be seen through the lens of late-forming generalist circuits overtaking memorizing ones, they argue grokking is a widespread dynamic. Huang et al. delineated how increasing model capacity or data can move a model between the four regimes (no-fit, memorize, grok, comprehend)arxiv.org. This suggests, for example, that a sufficiently large model might not grok (it jumps straight to generalization, the comprehension phase) – which might explain why grokking is harder to notice in very large-scale settings unless carefully analyzed. But in intermediate regimes (including many practical scenarios), we might expect some grokking-like behaviors.
Other Model-Agnostic Findings: Additional works have explored simplified theoretical models of grokking. For instance, Levi et al. (2023) analyzed a linear estimator that groks – they constructed a solvable setup (linear regression with particular features) where the solution exhibits a delayed generalization effect, giving a fully analytical handle on grokking dynamics. Lyu et al. (2023) proved in a theoretical setting that a “dichotomy of early vs. late implicit bias” in gradient descent could provably lead to grokking-like behavior (early training minimizes training error in one way, later dynamics of gradient descent shift the solution towards a different minimum with better generalization)gwern.net. These works support the notion that grokking can emerge from general properties of optimization in high-dimensional systems, not just quirky neural network tricks.
The upshot is that grokking generalizes beyond its initial context. It has been replicated in kernel methods, probabilistic models, and deeper nets, and connected to phenomena like double descent and phase transitions. This broadens confidence that grokking reveals something fundamental about learning: there can be multiple qualitatively different regimes during training, and the final generalization behavior may be decided by a late-time dynamical shift rather than evident early on.
Applications in LLM Pretraining
A critical question is whether grokking occurs in large-scale, real-world training, such as the pretraining of large language models (LLMs). For a long time, grokking was mostly a toy-setting curiosity. Recent studies in 2025 provide evidence that grokking does manifest during LLM pretraining – albeit in a more complex, asynchronous way – and that we can detect it via the model’s internal dynamics.
Grokking in Mixture-of-Experts LLM (Li et al., 2025): Li and colleagues conducted the first study of grokking in the context of a full-scale LLM pretraining run. They analyzed checkpoints from the training of OLMoE, a 7-billion-parameter Mixture-of-Experts transformer (so, a large model with multiple experts per layer)arxiv.orgarxiv.org. Crucially, they did not have a traditional held-out test set to watch accuracy during pretraining (since language model pretraining is unsupervised), so they crafted a methodology: they computed the model’s loss on its training data over time and also periodically evaluated the emergence of capabilities on various downstream tasks (math reasoning, code generation, factual QA) using intermediate checkpointsarxiv.orgarxiv.org. They indeed found that grokking-like delayed generalization happens in LLM pretrainingarxiv.org. However, unlike the toy tasks where suddenly all data is grokked at once, in LLMs different domains or skill areas grokked at different timesarxiv.orgarxiv.org. For example, perhaps the model’s performance on math word problems might remain low until very late in training (a “later grokking” capability), whereas its performance on commonsense QA might improve earlier. They called this “local grokking” – each subset of the training data (or each domain/task) has its own delayed generalization pointarxiv.org. Early in pretraining, the model’s generalization (when evaluated on downstream tasks) was unstable, improving on some tasks then dropping, etc., which they attribute to these asynchronous grokking events across domainsarxiv.org. Once sufficient data had been seen and memorized in a domain, that domain’s test performance started improving steadilyarxiv.org. Notably, more difficult data (or tasks) grokked later and had longer delays, which aligns with intuition – complex patterns take longer for the model to discover even after fitting the easier partsarxiv.orgarxiv.org.
Routing Dynamics as Generalization Indicators: Because evaluating an LLM on test tasks in the middle of pretraining is expensive and confounded (since the model isn’t instruction-tuned yet), Li et al. proposed to monitor internal model metrics instead. In a Mixture-of-Experts (MoE) model, a routing network directs each input to certain expert sub-networks at each layer. Li et al. tracked the expert choice patterns (pathways) for training samples throughout trainingarxiv.orgarxiv.org. They discovered an intriguing mechanistic change: during grokking, the expert pathways for different samples go from being random and instance-specific to becoming more structured and shared among samplesarxiv.orgarxiv.org. In other words, early in training each data point might activate a unique sequence of experts (suggesting rote memorization of individual quirks), but later in training, the model converges on more uniform pathways that generalize across examples (suggesting it found common patterns)arxiv.orgarxiv.org. Additionally, they defined a “pathway complexity” measure (essentially, how complicated a single sample’s expert route is). They observed that even though training loss had plateaued, the pathway complexity of samples kept decreasing as training continuedarxiv.orgarxiv.org. This means the model was finding simpler internal explanations for each sample (using fewer or more consistent experts) without any change in loss – a clear indicator of memorization turning into generalization internally. These changes in routing behavior strongly correlated with actual downstream performance gainsarxiv.orgarxiv.org. Based on this, the authors proposed two metrics: (1) Pathway distance between samples – measuring if inputs start to share similar expert routes, and (2) Pathway consistency for a sample – measuring if a single input’s route becomes more stable/simple layer-to-layerarxiv.org. Both metrics showed a marked shift exactly when generalization (as measured by downstream tasks) improvedarxiv.orgarxiv.org. Impressively, these metrics can be computed without any test data: they rely only on the model’s internal choices on training data. This offers a potentially powerful tool: monitoring generalization in large-scale training without needing a validation setarxiv.orgarxiv.org. In practical terms, one could decide when a pretraining run has effectively “grokked” its data and is ready, by looking at the trends of these routing metrics – useful for early stopping or dynamic scheduling of trainingarxiv.orgarxiv.org. The authors also provided theoretical grounding for why more structured pathways imply better generalization: in a one-layer MoE, they prove that if the routing function clusters inputs (i.e., pathways are shared) the model’s effective complexity is lower and yields a tighter generalization boundarxiv.orgarxiv.org.
Mechanistic Interpretability in LLMs: While the routing analysis is one form of mechanistic insight, there are also efforts to directly interpret what large models are learning during grokking. For example, one could attempt to identify emerging neurons or circuits corresponding to new abilities that activate late in training. The study “Grokked Transformers are Implicit Reasoners” (Wang et al., 2024) examines whether after grokking, transformers effectively perform multi-step reasoning without explicit chain-of-thought – suggesting grokking might coincide with the network internalizing implicit algorithms. They found that small transformers trained to grok a reasoning task ended up using their feedforward layers to carry out multi-step logical inferences implicitly (hence “implicit reasoners”). This again underscores that when a model groks, it often has discovered an interpretable algorithm or structure internally (like a reasoning procedure or a Fourier transform, as earlier cases showed). Such mechanistic studies on larger models are just beginning, but they promise to connect emergent behaviors in LLMs to the grokking framework.
In summary, grokking does occur in large-scale LLM training, but it’s more nuanced: not all tasks grok at once (some skills emerge earlier or later than others), and we need clever metrics to catch it since we can’t rely on simple train/test loss curves in one-pass trainingarxiv.orgarxiv.org. The MoE study provides encouraging evidence that even in a 7B model trained on a diverse corpus, one can see telltale signs of grokking in the model’s routing patterns and representation complexityarxiv.orgarxiv.org. This bridges the gap from toy problems to real-world foundation models, implying that the lessons learned about grokking (e.g. importance of continued training past apparent convergence, internal competition of circuits) are relevant for understanding how LLMs acquire capabilities over the course of training.
Current Challenges and Future Research Directions
Despite significant progress in understanding grokking, several challenges and open questions remain:
Limitations of Current Studies: Thus far, many grokking investigations have been on toy tasks or small models. Algorithmic operations (modular arithmetic, group theory tasks) have been the prototypical setting because they cleanly demonstrate delayed generalizationar5iv.labs.arxiv.orgar5iv.labs.arxiv.org. A concern is how well conclusions transfer to more complex, noisy tasks or datasets. For instance, natural data may not exhibit as stark a plateau or jump; instead, partial or domain-specific grokking (as seen in LLMs) might be more commonarxiv.orgarxiv.org. Additionally, most mechanistic interpretability success (e.g. fully reverse-engineering the Fourier addition circuitarxiv.org) has been on very small networks. Scaling those methods to interpret a grokking event in a billion-parameter model is non-trivial. Future work needs to test grokking in a wider array of tasks – e.g., does a vision model ever grok a pattern in image data? If not, why not (is it data size, or architecture)? There’s early evidence of grokking in MNIST with distribution shiftsarxiv.orgarxiv.org, but more real-world cases would bolster the universality of the phenomenon.
Detecting and Leveraging Grokking in Large-Scale Training: One practical challenge is observability. In giant models trained on massive data, a small jump in aggregate validation loss might be hard to notice or attribute to a grokking-like dynamic. As Li et al. (2025) noted, generalization gains might be asynchronous and spread over trainingarxiv.orgarxiv.org. We might need to develop new metrics or probes to detect grokking in such settings. The pathway complexity metrics discussed above are a promising startarxiv.orgarxiv.org. Another idea is using training dynamics modeling (e.g., “predicting grokking long before it happens” – Notsawo et al., 2023 used loss landscape analysis to anticipate a coming grokking eventgwern.net). If we can predict that a model will grok given enough time, we can manage training accordingly. This ties into training efficiency and early stopping: A big risk today is stopping training too early when the validation loss plateaus; grokking teaches us that apparent convergence may mask potential future gains. But we also don’t want to waste compute if no grokking is forthcoming. So a future direction is developing early-warning signals for grokking – e.g., monitoring internal feature rank (per Fan et al.arxiv.org) or pathway metrics (per Li et al.arxiv.org) to know that the model is in a “memorization plateau but actively reorganizing internally,” as opposed to truly stuck. Carvalho et al. explicitly mention using their insights on distribution shifts to inform better stopping criteriaarxiv.org. For example, if one detects that the model has not yet learned relationships between subclasses (via some probe), one might decide to continue training longer or adjust training to facilitate that.
Scaling Mechanistic Interpretability: One fascinating direction is applying mechanistic interpretability at scale to grokking. The small-scale studies literally found the circuit (e.g., discrete Fourier transform) the model usedarxiv.org. In a larger model, say an LLM, can we identify a subnetwork or set of neurons that implemented a new capability at the moment it grokked that capability? If so, we could potentially see an emergent chain-of-thought or algorithm form. This could connect to research on phase changes in model behavior – e.g., if an LLM suddenly learns to do multi-step reasoning, is there an internal circuit that “snaps” into place? Grokking provides a controlled way to study such phase changes. Phase transition analyses (like calculating order parameters for when a network’s representation changes qualitatively) could be borrowed from physics more in the future, continuing the work of Liu et al.’s phase diagramspapers.neurips.ccpapers.neurips.cc.
Understanding the Role of Regularization and Optimization: Many works noted that weight decay (or implicit regularization) was important for grokkingar5iv.labs.arxiv.org. Why exactly? Does it simply slow down memorization enough for feature learning to catch up (as Power et al. intuitedar5iv.labs.arxiv.org)? Or does it actively favor low-complexity circuits, tipping the competition? Similarly, optimizer choices might matter: an AdamW vs. SGD might traverse the loss landscape differently in the plateau. There was a paper by Thilak et al. (2022) on the “Slingshot Mechanism” that looked at adaptive optimizers and grokking, suggesting that certain optimizer behaviors (like overshooting and retracing in loss) can facilitate escaping a memorization minimumgwern.net. Future work can explore how different training algorithms influence the lazy-to-rich transition or circuit formation. This might inform best practices – e.g., if we want a model to grok a solution, should we use a smaller learning rate initially (to encourage lazy training) and then increase it?
Grokkability of Tasks and Models: It remains an open question which tasks are grokkable. Clearly, tasks that have an underlying exact structure (group theory, arithmetic) exhibit grokking. Tasks that are purely memorization (random mapping) would never grok because there is no structure to find. Most real tasks lie between – they have patterns plus idiosyncrasies. One could define a measure of a task’s “learnability gap”: how much better could a model potentially do if it discovered an optimal representation vs. just memorizing? Perhaps tasks with a large gap are likely to produce grokking if the model size/data regime is right. There is also the question of model architecture: do some architectures lend themselves to grokking more? (Transformers vs RNNs vs CNNs, etc.) The evidence so far (transformers, MLPs, even GPs) suggests it’s broad, but perhaps recurrent models might behave differently due to how they process data.
Practical Implications – Training Strategy: If grokking can be achieved, could we intentionally leverage it to train models more efficiently? For example, one might deliberately train on a smaller subset of data until grokking occurs (to force the model to find a general solution under constrained data), then fine-tune on more data. This might yield a better generalizing model than training on all data from scratch (where the model might memorize more). This is speculative, but it relates to curriculum learning: small data induced grokking might act like a curriculum that teaches the model an underlying concept which then helps on bigger data. On the flip side, grokking also implies wasted time in training (the long plateau). If we understand it well, we could try to shorten that plateau (e.g. via hyperparameter tuning or auxiliary losses that encourage the general solution sooner). Work like “Grokfast: Accelerated Grokking by Amplifying Slow Gradients” (Lee et al., 2024) explicitly looked at speeding up grokking by modifying the training dynamics to amplify the learning signal of the true pattern. Continuing such research can make grokking less of an oddity and more of a tool.
Theoretical Questions: The convergence properties of grokking are not fully understood. Why does the generalization often snap almost vertically? Is there a bifurcation in the gradient flow dynamics underlying that? Some have drawn analogies to phase transitions in physics, where an order parameter changes rapidly once a threshold is passedpapers.neurips.ccpapers.neurips.cc. Connecting formal learning theory to grokking is challenging, but one could imagine analyzing a simplified model of grokking as a dynamical system with multiple attractors (a memorization attractor and a generalization attractor). Recent work by Žunkovič & Ilievski (2022) indeed studied “grokking phase transitions” in learning local rules, noting parallels to physical systemsgwern.net. Bridging these perspectives could yield a more rigorous definition of when grokking occurs (perhaps in terms of a threshold on data size relative to model complexity, as hinted by Liu et al. with a critical dataset fractionpapers.neurips.cc, or a threshold on alignment of model’s eigenfunctions with the target as per Kumar et al.openreview.net).
Emergent Abilities and Grokking: As Huang et al. argue, emergent abilities in very large models might be essentially grokking happening along the scale axisarxiv.org. This raises an exciting prospect: by studying grokking in controlled settings, can we predict what abilities will emerge in frontier models and at what point? For example, if we treat a certain complex task as a “held-out capability,” can we estimate how much data or model size is needed before that task’s solution “clicks” (grokks) into place? Research by Zhu et al. (2024) on “Critical data size of language models from a grokking perspective” touches on this – finding the minimum data required for an LLM to grok linguistic phenomenagwern.net. This kind of research could guide dataset design: if some ability hasn’t emerged, maybe more data or a different training regimen is needed to induce a grokking event.
Safety and Alignment Considerations: An interesting side note is that grokking implies models can harbor latent capabilities that only activate after extensive training. For AI alignment, this is a double-edged sword: on one hand, it means a model might unexpectedly become capable (which could be risky if the capability is misaligned); on the other hand, monitoring for grokking-like shifts (via interpretability tools) might alert us to sudden capability gains. Research in mechanistic interpretability born out of alignment (like Nanda’s work) is likely to continue leveraging grokking as a testbed.
In conclusion, grokking has graduated from a curious phenomenon on toy data to a concept that links a variety of deep learning mysteries: generalization dynamics, double descent, emergence, and more. Current challenges revolve around scaling our understanding and detection of grokking to realistic settings and harnessing it for positive ends (improving training, predicting emergent behaviors). Future research will likely focus on unifying theoretical models, developing new diagnostics for ongoing training, and applying these ideas to ever larger models to see just how ubiquitous delayed generalization is. Grokking has essentially opened a new window into the time dimension of learning: it reminds us that when a model learns can be as fascinating as whether it learns at all.
Summary of Key Papers on Grokking
The table below summarizes major papers discussed, including their core contributions and methodologies:
| Paper (Authors, Year) | Core Findings | Methodologies | Contributions / Open Issues |
|---|---|---|---|
| Power et al., 2022 – “Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets”ar5iv.labs.arxiv.orgar5iv.labs.arxiv.org | Discovered grokking (delayed generalization) in small neural networks on algorithmic tasks. Validation accuracy jumped from random to 100% long after training accuracy was 100%. Smaller datasets cause longer delays; weight decay accelerates generalizationar5iv.labs.arxiv.orgar5iv.labs.arxiv.org. | Empirical study on small transformers (modular arithmetic operations). Monitored train/test curves for various dataset sizes and hyperparametersar5iv.labs.arxiv.orgar5iv.labs.arxiv.org. | Introduced the term “grokking” and its key traits. Highlighted the role of data size and regularizationar5iv.labs.arxiv.org. Provided an open-source testbed for studying generalization beyond memorization. Open issues: initially lacked a clear explanation of mechanism (spurred follow-ups). |
| Liu et al., 2022 – “Towards Understanding Grokking: An Effective Theory of Representation Learning”papers.neurips.ccpapers.neurips.cc | Proposed a phase diagram of learning with four phases: confusion, memorization, grokking (delayed gen), comprehension (immediate gen). Showed representation learning occurs only in a “Goldilocks zone” between memorization and confusionpapers.neurips.cc. Grokking phase is nearer memorization, causing delaypapers.neurips.cc. Hyperparameters determine phase; proper tuning can eliminate grokking (move to comprehension)papers.neurips.ccpapers.neurips.cc. | Both theoretical (effective theory) and empirical: developed an analytic toy model predicting a phase transition in representation quality vs. data fractionpapers.neurips.cc; ran grid searches to produce phase diagrams for transformer models on tasks (addition, permutation groups)papers.neurips.ccpapers.neurips.cc. | Gave an intuitive “comprehension–grokking–memorization” frameworkpapers.neurips.cc. Introduced physics-inspired analysis (phase transitions, “intelligence from starvation” analogy)papers.neurips.cc. Contribution: explained grokking as hyperparameter mis-tuning and provided a path to “de-delay” generalizationpapers.neurips.cc. Open issues: applicability of phase diagrams to complex tasks; defining Goldilocks zone quantitatively. |
| Kumar et al., 2024 – “Grokking as the Transition from Lazy to Rich Training Dynamics”openreview.netopenreview.net | Explained grokking via a two-regime dynamic: initially lazy training (network acts nearly linear/NTK, fits training data without feature change), later transitions to rich feature learning, yielding generalizationopenreview.netopenreview.net. Key determinants: misalignment of initial kernel and target, dataset size in an intermediate range, and small initial learning rate to enforce lazy startopenreview.netopenreview.net. Showed this transition causes test loss to plummet late. | Theoretical analysis on a polynomial regression task with a 2-layer ReLU network; derived sufficient statistics for test lossarxiv.orgarxiv.org. Empirical demonstrations on simple tasks and extensions to MNIST and small transformersopenreview.netopenreview.net. | Provided a clear mechanistic story for delayed generalization in terms of kernel vs. feature-learning regimesopenreview.net. Bridged grokking with classical NTK theory. Contribution: identified controllable factors (feature learning rate, etc.) to induce or prevent grokkingopenreview.net. Open question: how to measure “lazy vs rich” in large-scale nets in real-time; linking to implicit bias in GD. |
| Nanda et al., 2023 – “Progress Measures for Grokking via Mechanistic Interpretability”arxiv.org | Conducted full reverse-engineering of a grokking model’s algorithm. Found model learned modular addition via Fourier transformsarxiv.org. Defined three training phases: memorization, circuit formation, cleanup, and showed grokking is the result of a gradual increase of the algorithmic circuit’s strength and removal of memorizing componentsarxiv.org (not a truly instantaneous jump). Developed continuous progress measures that split training into phases. | Mechanistic interpretability on a small transformer (mod 97 addition): traced neuron values, discovered Fourier basis in embeddingsarxiv.org; performed ablations and “circuit tests” (e.g. intervening in Fourier-space) to confirm the learned algorithmarxiv.org. Tracked metrics like circuit strength over thousands of training steps. | Demonstrated that grokking has interpretable internal dynamics (not magic). Introduced the idea of competing circuits (memorization vs. generalization) and provided evidence with clean metricsarxiv.org. Contribution: showed a path to quantify emergence (progress measures), inspiring others to find such measures in larger models. Open issues: scaling this approach beyond toy settings; identifying progress measures in high-dimensional models. |
| Carvalho et al., 2025 – “Grokking Explained: A Statistical Phenomenon”arxiv.orgarxiv.org | Argues grokking arises from a distribution shift between train and test. Showed that imbalanced sampling of classes and subclasses can systematically produce grokkingarxiv.orgarxiv.org – the model overfits to frequent substructures then later leverages relationships to handle rare ones (delayed gen). Demonstrated grokking with dense data and minimal regularization if a latent shift existsarxiv.org. Validated on synthetic datasets (equidistant and equivariant subclass structures) and even induced a grokking-like effect on MNIST via clustered distortionsarxiv.orgarxiv.org. | Statistical analysis and dataset design: created synthetic classification tasks with controllable subclass sampling to induce or remove distribution shiftsarxiv.org. Monitored training dynamics and final accuracy under different sampling regimes. Also did an experiment on a real dataset (MNIST) by clustering digit styles to simulate domain shiftarxiv.orgarxiv.org. | Brought a data-centric view: highlighted that small data is a proxy for distribution gaps, not the sole cause of grokkingarxiv.orgarxiv.org. Contribution: showed one can trigger or prevent grokking by tweaking data composition, implying potential control over late generalization. Suggests using insights for better early stopping – e.g. detect when a model might grok by looking at data subsets performancearxiv.org. Open issues: how general is this to other forms of distribution shift? Can we quantify “how much shift causes how much delay”? |
| Miller et al., 2023 – “Grokking Beyond Neural Networks: An Empirical Exploration with Model Complexity”arxiv.orgarxiv.org | Discovered that grokking-like delayed generalization occurs in non-neural models too: observed in Gaussian Process classifiers, GP regression, linear regression, and Bayesian neural netsarxiv.org. Concluded that any learning system where solutions trade off complexity and error could grok. Also showed adding extraneous “decoy” features to the input can induce grokking by encouraging an initial memorizing solution which is later abandonedarxiv.org. | Empirical experiments mirroring neural grokking but with other models: e.g. training a GP on a small algorithmic dataset and tracking when its posterior starts to generalize; analytical discussion of linear regression under certain feature setups. Complexity-guided search perspective used to interpret results. | Generalized the scope of grokking beyond deep learningarxiv.org. This suggests grokking is about solution selection dynamics, not just SGD quirk. Important contribution: implies theories of grokking should also apply to kernel methods and even analytic learners – a direction for future theoretical work. Open issues: can we formally prove grokking in, say, Gaussian processes or linear models? What does this mean for using grokking to select inductive biases? |
| Fan et al., 2024 – “Deep Grokking: Would Deep Neural Networks Generalize Better?”arxiv.org | Showed that deeper networks (12-layer MLPs) not only grok but can have multiple generalization surges (“multi-stage grokking”)arxiv.org. Noticed a secondary jump in test accuracy in deep nets (absent in shallow nets) and correlated this with feature rank dynamics: internal feature rank drops at each generalization jumparxiv.org. Identified a double-descent pattern in feature rank (complexity) corresponding to the grokking stagesarxiv.org. Suggests internal representation compression is an indicator of grokking progress. | Experimental study varying network depth on modular tasks. Measured layer-wise feature rank (via SVD or PCA of activations) throughout trainingarxiv.org. Compared training trajectories of deep vs. shallow models, noting differences in test accuracy curves and complexity measures. | Extended grokking analysis to deep architectures, emphasizing that depth increases the propensity for delayed yet eventual generalizationarxiv.org. Contribution: proposed feature rank as a proxy for generalization readinessarxiv.org – a potential tool for monitoring training. Also connected grokking with the phenomenon of double descent in a new way (via feature complexity)arxiv.org. Open question: can feature rank metrics be used in practice to decide training schedules? Why do deep nets have multiple grokking phases – is it hierarchical learning of sub-concepts? |
| Huang et al., 2024 – “Unified View of Grokking, Double Descent and Emergent Abilities: A Perspective from Circuits Competition”arxiv.orgarxiv.org | Presented a unifying framework where a model’s training behavior is governed by competition between memorization circuits vs. generalization circuitsarxiv.org. Used this to explain three phenomena: grokking (time-based competition where generalization circuit wins late), double descent (model-size-based competition – test error spikes when mem circuits dominate at medium model sizes, then falls as gen circuits dominate in larger models)arxiv.orgarxiv.org, and emergent abilities in multi-task LLMs (task-wise competition – a new ability “emerges” when model/data scale allows a generalist solution for that task to overcome trivial solutions)arxiv.org. Mapped out four regimes of training dynamics (depending on model capacity & data): confusion, memorization, grokking, comprehensionarxiv.org. Made testable predictions about double descent thresholds, confirmed by experiments. | Theoretical framework building on prior grokking interpretation, extended to larger-scale phenomena. Provided conceptual arguments and some empirical validation on algorithmic tasks with varying model sizes and multi-task setupsarxiv.orgarxiv.org. For emergent abilities, framed algorithmic tasks in a multi-task environment to show how a new task’s performance stays low then jumps as model scales. | Synthesis contribution: Connected grokking to other deep learning mysteries under one lensarxiv.org. Emphasized the universality of the “two-circuits” competition as a driver of non-linear generalization effects. Provides a mental model for researchers: e.g., if you see double descent, think of it as “grokking across model sizes.” It also suggests practical insight: to avoid poor generalization, ensure conditions where generalization circuits dominate early (more data or regularization to suppress pure memorization). Open issues: how to identify these “circuits” in real networks; extending the unified framework to continuous spectra of solutions (not just binary mem vs gen). |
| Li et al., 2025 – “Where to find Grokking in LLM Pretraining? Monitor Memorization-to-Generalization without Test”arxiv.orgarxiv.org | Provided the first evidence that grokking happens during large-scale LLM pretraining, though asynchronously across domains. Different skill areas in a 7B MoE model “grok” (show late generalization) at different timesarxiv.org. Importantly, introduced internal routing metrics to detect grokking: as training continues, Mixture-of-Expert routing patterns become more shared and simpler, indicating a shift from memorizing each example separately to generalizing across examplesarxiv.orgarxiv.org. Developed metrics (pathway distance between samples, pathway consistency for single sample) that predict downstream test improvementsarxiv.orgarxiv.org. These metrics allow monitoring generalization without a test set. Also grounded findings with a theoretical result linking structured pathways to improved generalization boundsarxiv.org. |