Executive Summary
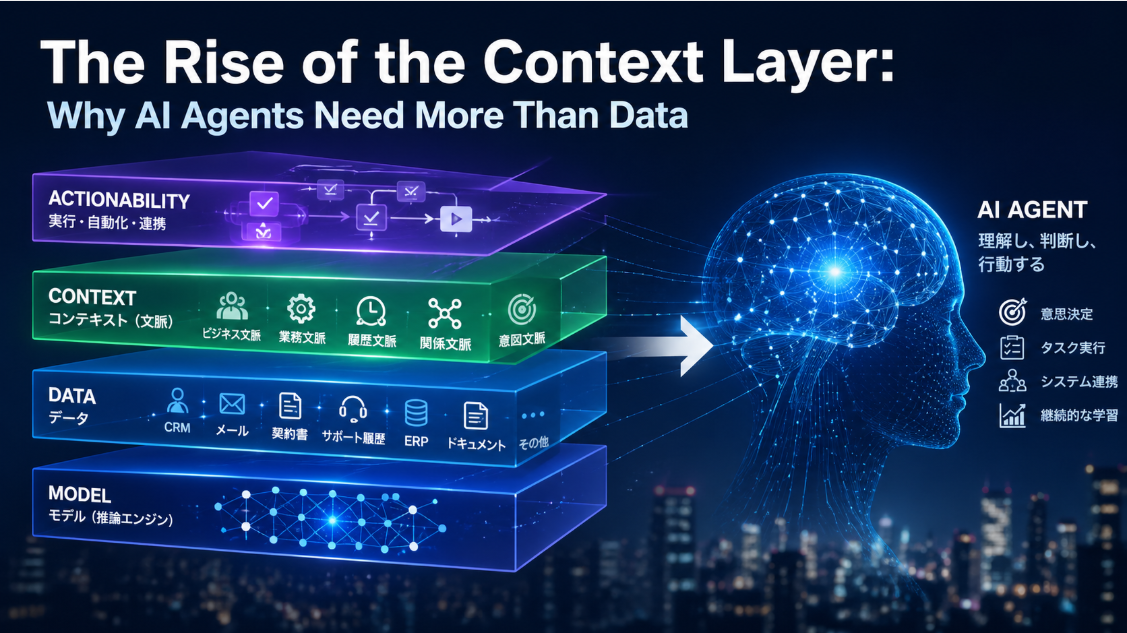
The core shift in enterprise knowledge systems is no longer just from “documents” to “LLMs.” It is from retrieving snippets toward structuring, navigating, editing, and exploring knowledge in forms that fit different kinds of work. Standard Retrieval-Augmented Generation, or RAG, remains the practical baseline because it is relatively easy to deploy, easy to update, and strong when the answer already exists in a small number of document fragments. Canonical and official sources describe the now-familiar pipeline: chunk documents, embed them, index them, retrieve relevant chunks, rerank them, inject them into context, and generate an answer. This improves grounding and can reduce hallucination relative to generation without retrieval, but it does not automatically solve search misses, fragmented context, or weak understanding of cross-document structure. (Lewis et al., 2020; Azure RAG overview; Azure chunking guide; Bedrock reranking; Lost in the Middle; IRCoT)
The newer architectures each address a different blind spot. GraphRAG adds an explicit graph layer so that the system can reason over entities, relations, communities, and whole-corpus themes, not just top-k chunks. LLM Wiki treats knowledge not as something to rediscover on every query, but as something an LLM continuously rewrites into a readable Markdown knowledge base. Corpus2Skill goes one step further toward agent operations: instead of retrieving top-ranked chunks at runtime, it compiles a corpus offline into a hierarchical skill directory that an agent can navigate through SKILL.md and INDEX.md files. Mindware Research Institute’s GNG+MST concept-structure approach points in a different but complementary direction: not “find the answer,” but “find the structure,” by visualizing clusters, concept distances, bridges, and latent exploration axes. (Microsoft GraphRAG paper; Microsoft GraphRAG docs; Karpathy, “LLM Wiki” gist; Corpus2Skill paper; Corpus2Skill GitHub; ThinkNavi manual; Mindware concept-investigation PDF)
The practical conclusion is that there is no single “post-RAG” architecture. The next phase is combinatorial by purpose. Use RAG for fast, grounded answers; GraphRAG when relationships and whole-corpus sensemaking matter; LLM Wiki when the organization needs an editable, compounding knowledge artifact; Corpus2Skill when agents must reliably traverse enterprise knowledge as an operational hierarchy; and GNG+MST when the goal is concept discovery, qualitative analysis, or research exploration rather than narrow question answering. The strategic design question is no longer “Which one replaces RAG?” but “Which representation of knowledge best fits the work we need to do?” (Azure RAG overview; Microsoft GraphRAG blog; ThinkNavi manual)
Title Proposals
- Beyond Retrieval: Where Knowledge Architecture in the LLM Era Is Heading
- From Search to Structure: RAG, GraphRAG, LLM Wiki, Corpus2Skill, and Concept Models
- The Next Knowledge Stack: Retrieval, Graphs, Wikis, Skills, and Concept Structure
Why Knowledge Architecture Is Shifting
Standard RAG remains the enterprise default because it is conceptually simple and operationally useful. In its common form, documents are chunked, chunk embeddings are computed, an index is built, a query triggers vector or hybrid retrieval, the candidate set is reranked, the top evidence is injected into the prompt, and the model generates an answer grounded in those retrieved fragments. Lewis et al.’s original RAG paper established the idea of combining a parametric model with non-parametric external memory, while Azure and Amazon Bedrock documentation make explicit the modern production pipeline: chunking, embedding, retrieval, reranking, and response generation. (Lewis et al., 2020; Azure RAG overview; Azure information retrieval guide; Bedrock reranking)

This pipeline is good at finding local answers. If the question is “What does the return policy say?” or “Which API parameter controls retries?” RAG often works well because the answer can be grounded in one or a few fragments. In that sense, RAG is like a strong search engine that can also write. It improves freshness and grounding relative to relying only on model parameters, and it can reduce hallucination when relevant evidence is actually retrieved. (Lewis et al., 2020; Self-RAG; Azure RAG overview)
But the limits have become increasingly visible. First, retrieval can simply miss the right evidence. BM25 is robust for lexical matches and remains a strong baseline, but it depends on term overlap and ranking heuristics; dense retrieval depends on embedding geometry and nearest-neighbor search; both can fail when the question is underspecified or when the necessary evidence is distributed across multiple documents. Second, chunking fragments context. A document may make sense as a whole even when no single chunk cleanly answers the question. Third, long context windows do not magically solve the issue, because models can still underuse relevant information placed in the middle of long prompts. Research such as IRCoT and Lost in the Middle shows why single-shot retrieve-and-read pipelines often struggle on multi-step reasoning and long-context use. (Stanford IR book on BM25; DPR; IRCoT; Lost in the Middle)
That is why the field is moving from pure retrieval toward knowledge forms better suited to different tasks. If RAG is a search box, GraphRAG is a map of connections, LLM Wiki is an edited handbook, Corpus2Skill is an agent-operable directory tree, and GNG+MST is a terrain map of meaning. The shift is not away from retrieval entirely, but away from assuming retrieval should be the only organizing principle. (Microsoft GraphRAG paper; Karpathy gist; Corpus2Skill paper; Mindware concept-investigation PDF)
Corpus2Skill in Detail
Corpus2Skill, introduced in the preprint “Don’t Retrieve, Navigate: Distilling Enterprise Knowledge into Navigable Agent Skills for QA and RAG” (arXiv: 2604.14572, April 2026) and implemented in the public repository dukesun99/Corpus2Skill, proposes a very specific inversion of the usual RAG assumption: do more work offline, so the runtime agent needs less retrieval and more guided navigation. The paper’s key claim is that enterprise knowledge can be distilled into a navigable skill hierarchy instead of a search index. The repository README describes the same idea in practical terms: take an arbitrary document corpus, compile it into a hierarchically arranged skill tree, and let the serving-time agent traverse that tree instead of querying a retrieval stack on every question. The repository is explicitly labeled an early release / work in progress, so it should be treated as promising but experimental. (Corpus2Skill paper; Corpus2Skill GitHub README)
Mechanistically, Corpus2Skill has an offline compile phase and a runtime serve phase. In the compile phase, the system reads the corpus, computes embeddings, clusters the corpus hierarchically, and uses an LLM to generate concise labels and summaries for each level. The public implementation specifies default models in the README, including Qwen/Qwen3-Embedding-0.6B for embeddings and claude-sonnet-4-6 for summarization at the time of the public README reviewed here. The output is a file-system-style hierarchy containing SKILL.md, INDEX.md, and document references. The paper explains that hard assignment is used so that each document lives on one path in the tree, making the hierarchy materializable as a directory structure. (Corpus2Skill GitHub README; Corpus2Skill paper)
At runtime, the agent does not begin by asking a vector database for the top-k nearest chunks. Instead, it begins with a high-level overview of the available skills and descends the tree. It reads a top-level SKILL.md, chooses a branch, opens lower-level INDEX.md files, and only then fetches source documents through a document lookup when needed. In other words, the agent is following a knowledge directory, not issuing repeated blind searches. That is the practical meaning of “navigate, don’t retrieve.” The knowledge base is pre-shaped into an explorable hierarchy, like moving through a company’s internal operations manual rather than typing keywords into a search bar. (Corpus2Skill paper)
This makes Corpus2Skill fundamentally different from both BM25 and standard vector-database RAG. BM25 ranks documents by lexical relevance using frequency-based scoring; dense retrieval ranks by embedding similarity; standard RAG usually turns those rankings into a top-k context pack for the model. Corpus2Skill still uses embeddings during compilation, but its runtime interface is not a ranked list of chunks. It is a navigation problem over a tree of summaries and directories. That matters because it gives the agent explicit “branching choices.” If a chosen path looks wrong, the agent can back up and try another branch, rather than being silently constrained by a possibly poor top-k retrieval result. (Stanford IR book on BM25; DPR; Corpus2Skill paper)
The paper evaluates Corpus2Skill on WixQA, a benchmark for enterprise support-style QA based on the Wix Help Center snapshot dated 2024-12-02. The Corpus2Skill paper reports, on the 200-query ExpertWritten split, a Token F1 of 0.460, compared with 0.342 for BM25, 0.363 for Dense, 0.389 for RAPTOR, and 0.388 for Agentic RAG. It also reports Factuality 0.729 and Context Recall 0.652, again above the reported baselines in that setting. The associated WixQA benchmark paper and dataset card describe the benchmark composition, including expert-written, simulated, and synthetic queries over the Wix knowledge base. These are strong results, but they should still be read as benchmark-specific evidence rather than universal proof. (Corpus2Skill paper; WixQA paper)
The trade-offs are equally important. Corpus2Skill’s runtime can be expensive because the skill files themselves consume input tokens. The paper reports roughly $0.172 per query in its main setting, and the public README says Anthropic prompt caching reduced that to $0.089 per query on the WixQA benchmark in repository testing. The paper also names several limitations: dependence on Anthropic’s Skills-style serving pattern, top-level routing errors caused by hard single-path clustering, and lack of mature support for incremental updates without recompilation. Those are not minor footnotes. They mean Corpus2Skill is best understood as a serious architectural idea at an early stage, not yet a drop-in replacement for every production RAG system. (Corpus2Skill paper; Corpus2Skill GitHub README)
Comparative Map of RAG, GraphRAG, LLM Wiki, and GNG+MST
Standard RAG is the retrieval-centered baseline. Its advantages are operational familiarity, modular indexing, relatively easy updates, and good performance on questions whose answers already exist in locally retrievable evidence. Its weaknesses are equally well known: search misses, chunk fragmentation, weak global structure, and the tendency to confuse “more retrieved text” with “better understanding.” (Lewis et al., 2020; Azure RAG overview)
GraphRAG, especially in Microsoft’s implementation, adds another layer of knowledge representation: extract entities, relations, and claims; detect communities; generate community reports; and support both local and global search modes. Global search is aimed at whole-corpus sensemaking, while local search starts from semantically relevant entities and expands into related neighborhoods. One practical detail from the official docs matters: GraphRAG does not necessarily require a dedicated graph database. Microsoft’s OSS implementation stores outputs in Parquet tables plus a vector store. Its real cost lies elsewhere: extraction quality, prompt tuning, report generation, hierarchy design, re-indexing, and operational maintenance. The docs openly state that out-of-the-box settings are not always optimal and that some features, such as claim extraction, require tuning to be useful. (Microsoft GraphRAG paper; Microsoft GraphRAG docs overview; Microsoft GraphRAG docs)
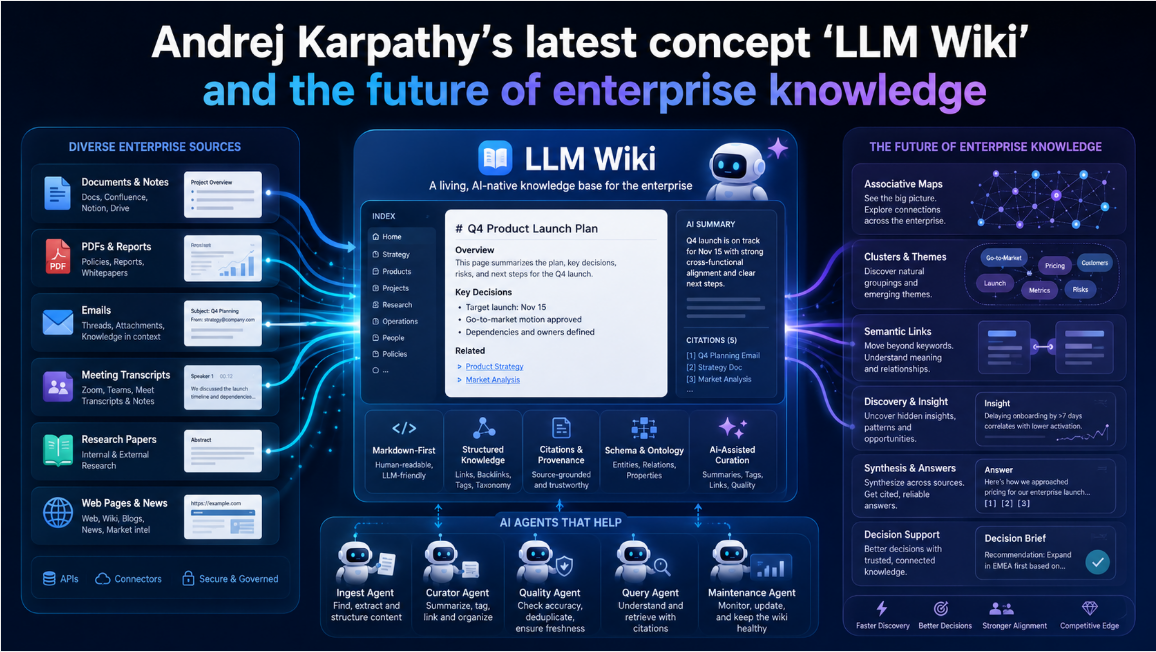
LLM Wiki, from Andrej Karpathy’s gist published on April 4, 2026, is not a product and not a benchmarked framework. It is a pattern. The key move is to convert raw sources into a persistent Markdown wiki that the LLM can read from, edit, and lint over time. Karpathy separates the system into raw sources, the wiki itself, and a schema or conventions layer. He also proposes three recurrent operations: ingest new sources, answer questions from wiki pages, and lint the wiki for contradictions, stale claims, and missing links. For personal or small-to-medium corpora, he argues that simple page indexes can work surprisingly well without a full embedding retrieval stack, roughly around the scale of about a hundred sources and hundreds of pages. That makes LLM Wiki especially relevant where the goal is knowledge compression, editing, and accumulation, not just one-shot retrieval. (Karpathy gist)
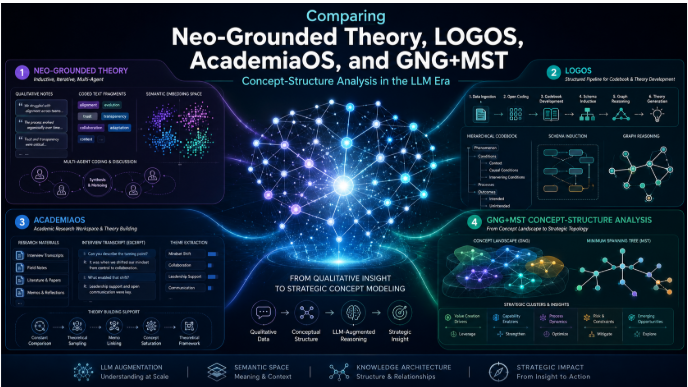
Mindware’s GNG+MST concept-structure approach comes from official ThinkNavi and ConceptMiner materials rather than a single canonical research paper. The public manuals and product pages describe a pipeline that uses embeddings and related data, organizes them with Growing Neural Gas and a Minimum Spanning Tree, and uses LLMs to help label dimensions, clusters, and semantic interpretations. The ThinkNavi manual contains the succinct formulation, “RAG finds answers. ThinkNavi finds structure.” That phrase is analytically useful. It captures the fact that this architecture is not primarily about point-answer retrieval. It is about surfacing conceptual neighborhoods, bridges, latent themes, exploration axes, and the relation between an embedding space and human-interpretable conceptual structure. Public official materials emphasize applications in strategic thinking, market or technology exploration, qualitative data analysis, and research support. What is not publicly confirmed in the official materials reviewed is a standardized external benchmark comparable to enterprise QA benchmarks such as WixQA. (ThinkNavi manual, chapter 1; ThinkNavi glossary/manual; ConceptMiner developer page; Mindware concept-investigation PDF)
The simplest way to remember the difference is by metaphor. RAG is a search engine. GraphRAG is a map of relations. LLM Wiki is a living handbook. Corpus2Skill is an agent-operable directory tree. GNG+MST is a terrain map of concepts. These are not interchangeable metaphors; they correspond to different knowledge representations and different operational burdens.
| Axis | Standard RAG | GraphRAG | LLM Wiki | Corpus2Skill | GNG+MST | Representative primary sources |
|---|---|---|---|---|---|---|
| Primary purpose | Ground answers with retrieved evidence | Capture relations and whole-corpus themes | Edit and accumulate knowledge into readable pages | Let agents traverse enterprise knowledge as skills | Visualize and explore conceptual structure | Lewis et al.; GraphRAG paper; Karpathy gist; Corpus2Skill; ThinkNavi |
| Input data | Documents, PDFs, FAQs, tickets | Unstructured text converted into entities/relations/claims | Raw source corpus | Document corpus compiled offline | Embeddings, text, and optionally related structured data | Azure RAG; GraphRAG docs; ConceptMiner |
| Knowledge representation | Chunks + embeddings + index | Graph + communities + reports + embeddings | Markdown pages + index/log + schema | SKILL.md, INDEX.md, document store, skill tree | GNG nodes, MST backbone, clusters, labeled dimensions | Corpus2Skill README; Karpathy gist; Mindware PDF |
| Search or exploration method | Retrieve top-k, often hybrid, then rerank | Global, local, and community-based graph search | Read indexes and linked pages; optional search | Descend a hierarchy, then fetch documents | Explore clusters, distances, bridges, sparse regions | Azure retrieval; GraphRAG docs; Corpus2Skill paper |
| Role of the LLM | Final answer generation; sometimes reranking and query rewrites | Extraction, summarization, report generation, answering | Writing, editing, querying, linting the wiki | Summarizing clusters and navigating the hierarchy | Labeling and interpreting concept structure | Bedrock rerank; Karpathy gist; ThinkNavi |
| Explicitness of structure | Low to moderate | High | High | High | High, but geometric rather than symbolic | GraphRAG paper; Mindware PDF |
| Update ease | Usually good | Moderate to difficult | Moderate; depends on wiki discipline | Lower; recompilation is an issue | Not publicly confirmed in detail | Azure RAG; Corpus2Skill paper |
| Scalability | High in common enterprise settings | Potentially high, but costly to build and maintain | Best for personal to medium corpora | Moderate; runtime pattern and hierarchy constraints matter | Public enterprise claim exists, external benchmark evidence limited | GraphRAG docs; Karpathy gist; ThinkNavi |
| Implementation and ops cost | Low to moderate | High | Moderate | Moderate to high | Moderate to high, platform-dependent | Azure RAG; GraphRAG docs; Corpus2Skill README |
| Best use cases | FAQ, internal search, support answers | Cross-document reasoning, relationship analysis, thematic summarization | Personal/team knowledge bases, reading and synthesis | Agent-facing enterprise support and procedural knowledge | Strategy, concept exploration, qualitative analysis, research support | WixQA; GraphRAG blog; Mindware PDF |
| Weak use cases | Global sensemaking, latent-theme discovery | Cheapest simple FAQ serving | Strict real-time retrieval at large scale | Highly dynamic corpora with frequent updates | Precision FAQ answer serving | Lost in the Middle; Corpus2Skill paper; ThinkNavi manual |
| Hallucination mitigation | Moderate if retrieval succeeds | Moderate to high when graph evidence is good | Moderate; edited knowledge helps, but summarization bias remains | Potentially strong for navigable grounding, but routing errors remain | Indirect; primary goal is structure, not answer grounding | Self-RAG; GraphRAG paper; Corpus2Skill paper |
| Enterprise suitability | High | Moderate to high | Moderate to high | High for stable knowledge domains | Moderate to high for analysis and exploration | Azure RAG; Corpus2Skill paper; ThinkNavi |
| Research suitability | Moderate | High | High | Moderate | Very high | GraphRAG paper; Karpathy gist; Mindware PDF |
Risks, Selection Guidance, and a Combined Hypothesis
Every architecture has a characteristic failure mode. In RAG, the classic problem is search omission: if retrieval misses the right evidence, grounding collapses. In GraphRAG, the main risk is upstream structuring error: bad entity extraction, poor relation extraction, or weak community summaries can distort downstream reasoning. In LLM Wiki, the risk is editorial bias: once the LLM rewrites and condenses the source material, errors can become persistent and culturally invisible because they now look like “organized knowledge.” In Corpus2Skill, the main risks are routing mistakes and recompilation burden: a document forced into one path may belong in several, and the hierarchy is not trivial to update incrementally. In GNG+MST, the difficulty is often evaluation: the value may lie in revealing a structure, white space, or bridge concept that no standard QA metric captures. (IRCoT; GraphRAG docs; Karpathy gist; Corpus2Skill paper; Mindware PDF)
For use-case selection, the practical pattern is straightforward. For FAQ and customer support, start with standard or hybrid RAG, and consider Corpus2Skill when the corpus is relatively stable and questions require agents to traverse several related support topics. For internal document search, standard RAG is still the sensible first layer, with GraphRAG added when cross-team relationships or thematic structure matter. For literature review or due diligence, LLM Wiki is powerful because knowledge compounds instead of being re-synthesized from scratch. For technical documentation exploration, use RAG for pinpoint lookup and Corpus2Skill if the user journey behaves more like following a structured troubleshooting tree. For strategy and market research, and especially for qualitative data analysis or new-business concept exploration, GNG+MST is especially attractive because the goal is often to expose latent themes, conceptual adjacency, and underexplored spaces rather than to answer a single factual question. (Azure RAG overview; Corpus2Skill paper; Karpathy gist; ConceptMiner)
The most interesting design hypothesis is that Corpus2Skill and GNG+MST may be complementary rather than competitive. This is a hypothesis, not a publicly confirmed integration. Corpus2Skill organizes knowledge into an agent-usable hierarchy. GNG+MST aims to discover the latent conceptual structure of a corpus: clusters, bridges, sparse zones, and exploration axes. If GNG+MST is good at revealing the hidden terrain of a knowledge space, then LLM Wiki or a similar editing layer could turn those discoveries into curated, human-readable knowledge pages, and Corpus2Skill could then compile those pages into an agent-operable skill tree. In that stack, concept discovery informs knowledge editing, and knowledge editing informs agent navigation. That would be a plausible architecture for enterprise research support, strategy work, and advanced knowledge platforms, but it remains a hypothesis until a public implementation or case study appears. (Mindware PDF; Karpathy gist; Corpus2Skill paper)

That is also why “the next thing after RAG” is the wrong question. The better question is: Which knowledge form best matches the work? Support answers need grounding. Strategy work needs pattern discovery. Agent workflows need navigation. Research synthesis needs editable accumulation. No single architecture does all of these equally well. (Microsoft GraphRAG blog; ThinkNavi manual)
Conclusion and References
The most defensible conclusion from primary and official sources is this: the future of knowledge architecture in the LLM era is plural, layered, and purpose-specific. RAG remains the default answer engine. GraphRAG extends that engine toward explicit relational structure and multi-document sensemaking. LLM Wiki treats knowledge as a living editorial artifact that compounds over time. Corpus2Skill reframes enterprise knowledge as a navigable hierarchy optimized for agent behavior. Mindware’s GNG+MST approach frames knowledge as conceptual terrain that can be explored for bridges, themes, and strategic white space. None of these makes the others obsolete. They solve different knowledge problems. (Lewis et al., 2020; GraphRAG paper; Karpathy gist; Corpus2Skill paper; ThinkNavi manual)
For practitioners, the decision rule is simple. If your question is “How do I answer correctly and cite evidence?” begin with RAG. If it becomes “How are these things connected across the corpus?” add GraphRAG. If it becomes “How do we build a durable, editable knowledge artifact instead of re-answering the same questions forever?” consider LLM Wiki. If it becomes “How do we let agents move through enterprise knowledge reliably?” evaluate Corpus2Skill. If it becomes “How do we discover themes, clusters, bridges, and unexplored directions?” look seriously at concept-structure approaches such as GNG+MST. In practice, the best enterprise architectures will often combine two or more of these layers rather than betting everything on one. (Azure RAG overview; Corpus2Skill paper; Mindware PDF)
A concise practitioner guide is below.
| Situation | Best starting point | Add next when needed |
|---|---|---|
| FAQ, help center, support answers | Standard or hybrid RAG | Corpus2Skill for navigable agent servicing |
| Internal document search | Standard RAG | GraphRAG for relation-level exploration |
| Literature review, due diligence | LLM Wiki | GraphRAG or GNG+MST for thematic structure |
| Product manuals and technical docs | RAG | Corpus2Skill for guided troubleshooting paths |
| Strategy and market research | GNG+MST | LLM Wiki for editorial consolidation |
| Qualitative data analysis | GNG+MST | GraphRAG for relation mapping |
| Agent-facing enterprise knowledge | Corpus2Skill | RAG fallback for direct evidence lookup |
References & Links
| Source | Type | Publication or update date | Notes |
|---|---|---|---|
| Lewis et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” | Paper | 2020 | Canonical RAG paper |
| Karpukhin et al., “Dense Passage Retrieval” | Paper | 2020 | Canonical dense retrieval reference |
| Asai et al., “Self-RAG” | Paper | 2023 | Retrieval, generation, critique loop |
| Trivedi et al., “IRCoT” | Paper | 2022 | Retrieval interleaved with chain-of-thought |
| Liu et al., “Lost in the Middle” | Paper | 2023 | Long-context placement effects |
| Azure AI Search: RAG overview | Official documentation | Update date not publicly confirmed here | Standard enterprise RAG pipeline |
| Azure AI Search: document chunking | Official documentation | Update date not publicly confirmed here | Chunking guidance |
| Azure architecture guide: RAG information retrieval | Official documentation | Update date not publicly confirmed here | Retrieval patterns |
| Amazon Bedrock: reranking | Official documentation | Update date not publicly confirmed here | Reranking stage |
| Microsoft Research, “From Local to Global: A Graph RAG Approach to Query-Focused Summarization” | Paper / research page | 2024 | Foundational GraphRAG paper |
| Microsoft GraphRAG documentation | Official documentation | Update date not publicly confirmed here | Current OSS reference |
| Microsoft GraphRAG overview | Official documentation | Update date not publicly confirmed here | Pipeline and data outputs |
| Microsoft Research blog on GraphRAG | Official blog | 2024 | Conceptual motivations and use cases |
| Yiqun Sun et al., “Don’t Retrieve, Navigate: Distilling Enterprise Knowledge into Navigable Agent Skills for QA and RAG” | Paper | April 2026 | Corpus2Skill primary paper |
| dukesun99/Corpus2Skill README | Official repository | Public repo; exact last-update date not confirmed here | Implementation details; early release status; cost note |
| WixQA benchmark paper | Paper | May 2025 | Enterprise support-style RAG benchmark |
| Andrej Karpathy, “LLM Wiki” gist | Primary gist | April 4, 2026 | Pattern proposal, not a product spec |
| ThinkNavi user manual, chapter 1 | Official manual | Update date not publicly confirmed here | Contains “RAG finds answers. ThinkNavi finds structure.” |
| ThinkNavi glossary/manual chapter | Official manual | Update date not publicly confirmed here | GNG/MST terminology |
| ThinkNavi about page | Official site | Update date not publicly confirmed here | Product positioning |
| ConceptMiner developer page | Official site | Update date not publicly confirmed here | GNG+MST and developer-facing description |
| Mindware Research Institute concept-investigation PDF | Official PDF | Publication date not publicly confirmed in the file path reviewed | Core conceptual explanation of GNG+MST as concept investigation |
Public-detail caveats. Corpus2Skill is publicly presented as an early release and experimentally promising; its portability beyond the current skills-centric serving pattern and its incremental-update story are not yet mature in the public materials. Karpathy’s LLM Wiki is intentionally abstract and pattern-oriented, not a standardized benchmarked system. GraphRAG is well documented but operationally heavy and tuning-sensitive. For Mindware’s GNG+MST materials, external benchmark-style validation comparable to enterprise QA benchmarks was not publicly confirmed in the official sources reviewed for this report.