This article summarizes and expands on a recent presentation by Singular Radio that explained the Hierarchical Reasoning Model (HRM) — an architecture that recently attracted attention for solving benchmark reasoning tasks with an extremely small parameter count. Singular Radio’s hosts walked through what HRM is, why it works, the biological inspirations behind the design, key engineering tricks that make training possible, experimental strengths and limits, and the implications for future AI systems. This written guide translates those spoken explanations into a detailed, structured overview, and adds clarifying examples and context so readers can understand not only how HRM works but why it matters.

Outline
- Introduction: Why HRM captured attention
- Background: Transformers, chain-of-thought, and the problems HRM addresses
- HRM architecture: high-level and low-level layers, recurrence, and adaptive computation
- Training innovations: segmentation, one-step approximate gradient, and memory updates
- Halting & decision mechanism: when to stop thinking
- Why HRM improves reasoning: depth by iteration and hierarchical refresh
- Biological inspirations: STDP, mixed selectivity, and multi-frequency processing
- Experimental results: puzzles, maze, ARC, and parameter efficiency
- Limitations and open questions
- Practical implications and possible hybrids with LLMs
- Conclusion: Where HRM fits in the future of AI
Introduction: Why HRM Captured Attention
In a field dominated by ever-larger transformer-based models, the Hierarchical Reasoning Model (HRM) grabbed attention for two striking reasons. First, it solved several classic reasoning benchmarks that large language models often struggle with—like structured number puzzles (a grid-reading task similar to Sudoku), mazes, and logical IQ-style problems—despite having a very small parameter count. Second, HRM was explicitly inspired by biological features of the mammalian brain, using a two-frequency hierarchical design that resembles slow high-level processing and faster low-level processing.
To put the scale into perspective: HRM variants reported strong results while being on the order of tens of millions of parameters (the presentation mentioned a model with roughly 27 million parameters), whereas state-of-the-art LLMs like ChatGPT are often described in the trillions of parameters when considering the largest combined systems. That gap makes HRM’s results surprising and invites a closer look at how architecture and training details can sometimes outweigh pure scale.
Background: Transformers, Chain-of-Thought, and Their Limitations
To understand HRM, it’s essential to revisit the transformer-based approach used by GPT-style models and the chain-of-thought (CoT) technique that improved reasoning performance.
How GPT-style Transformers Work (A Quick Recap)
At a high level, GPT-style models are trained to predict the next token in a sequence. Given a prompt like “Shohei Ohtani plays the sport…,” a properly trained model predicts “baseball” as the next token because of statistical associations learned from large text corpora. These systems rely on multi-layer transformer stacks: tokens are embedded into vectors, attention layers process context, and a decoder-style transformer predicts next tokens. The architecture’s performance historically scales with depth, width, and parameter count.
Chain-of-Thought (CoT)
Chain-of-thought is a prompting or training technique that instructs a model to produce intermediate reasoning steps explicitly as text. Instead of directly predicting the final answer token, a model produces a sequence of reasoning steps and then the final answer. This practice has improved performance across arithmetic, logic, and some math olympiad tasks because it forces the model to expose and refine intermediate reasoning.
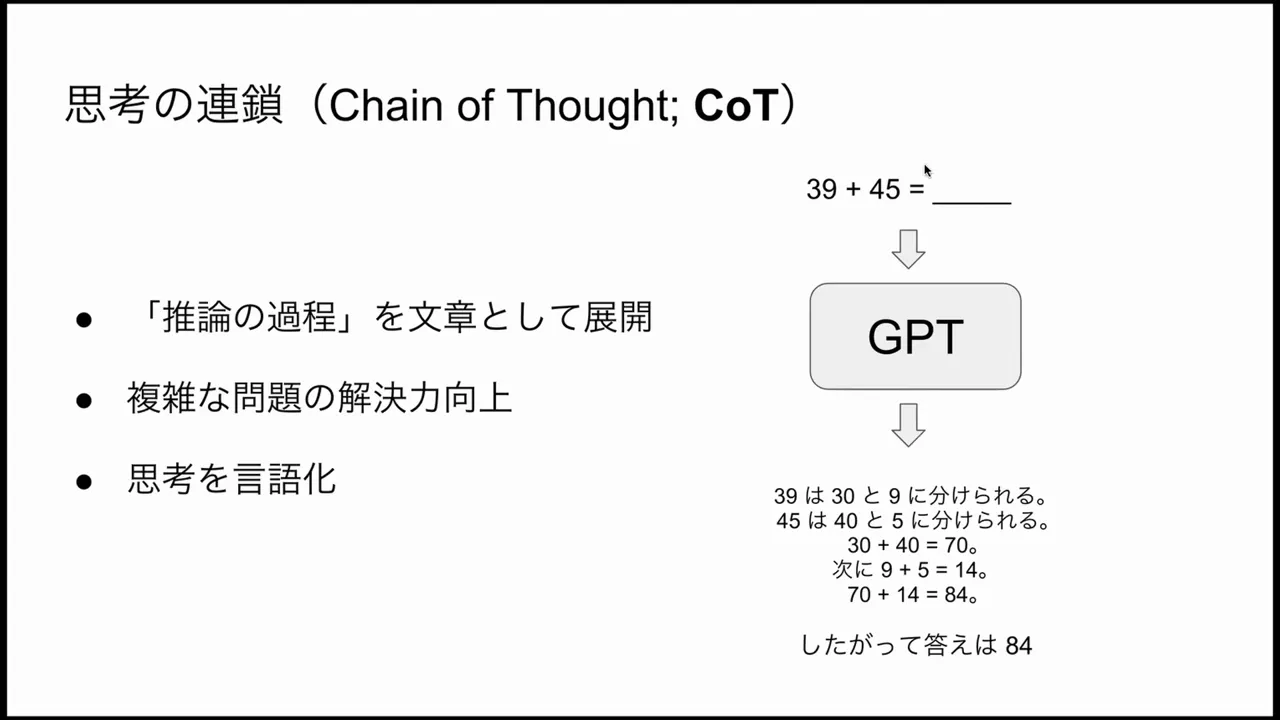
Key Limitations of Transformer + CoT
- Fixed depth: Transformer architectures have a fixed number of layers. That means every input is processed through the same depth regardless of problem complexity. Simple tasks may be over-processed, and complex tasks may not receive enough computational depth.
- Data inefficiency: Modern transformers typically require massive pretraining on internet-scale datasets. They are not always data-efficient for domain-specific reasoning tasks unless extensively fine-tuned.
- Language dependence: CoT relies on language to represent intermediate reasoning. But not every cognitive process is naturally verbalizable; some reasoning is better represented in internal, non-linguistic latent spaces.
- Latent convergence and slow inference: Iterative reasoning via CoT can slow outputs, and repeating similar layers does not guarantee deeper reasoning because internal states can converge prematurely.

These limitations motivated HRM to rethink how depth and iteration are handled, how to control computation per instance, and how to preserve internal latent reasoning without forcing verbose verbalization.
HRM Architecture: Hierarchy, Recurrence, and Adaptive Compute
HRM stands for Hierarchical Reasoning Model. The core architectural idea is deceptively simple: combine a small number of hierarchical layers with iterative recurrence to emulate “depth” via time rather than stacking thousands of layers.
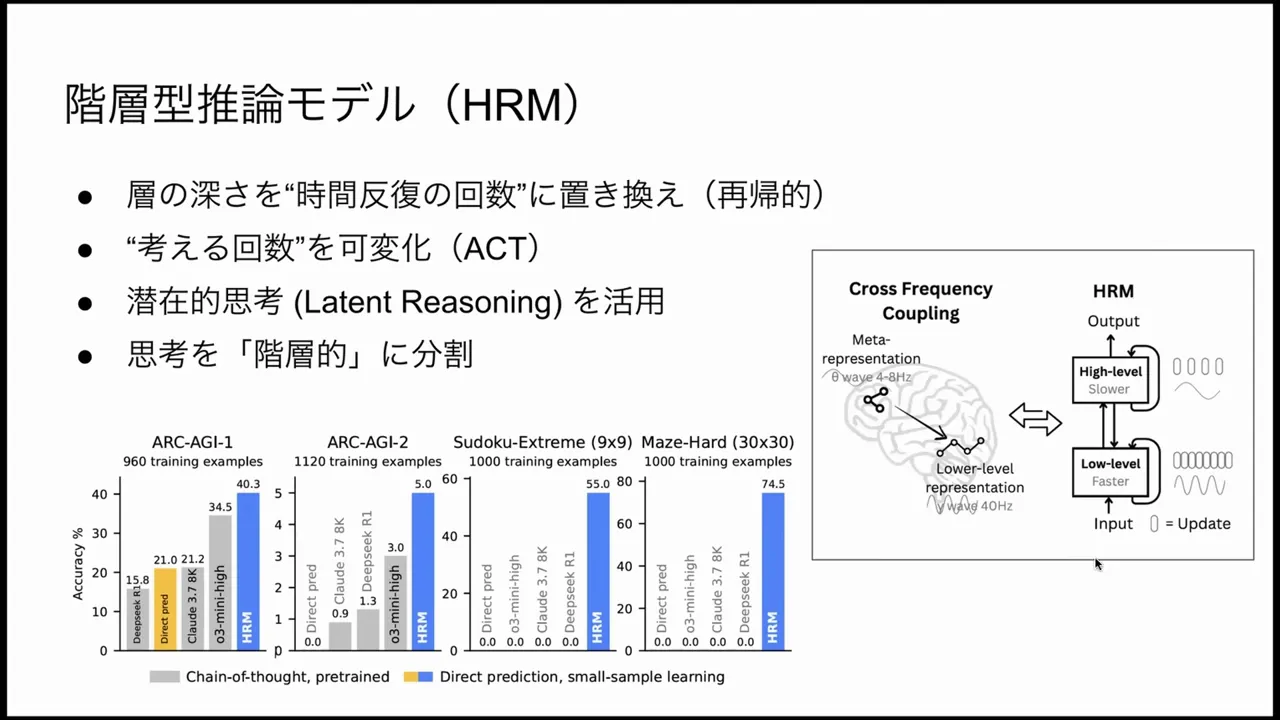
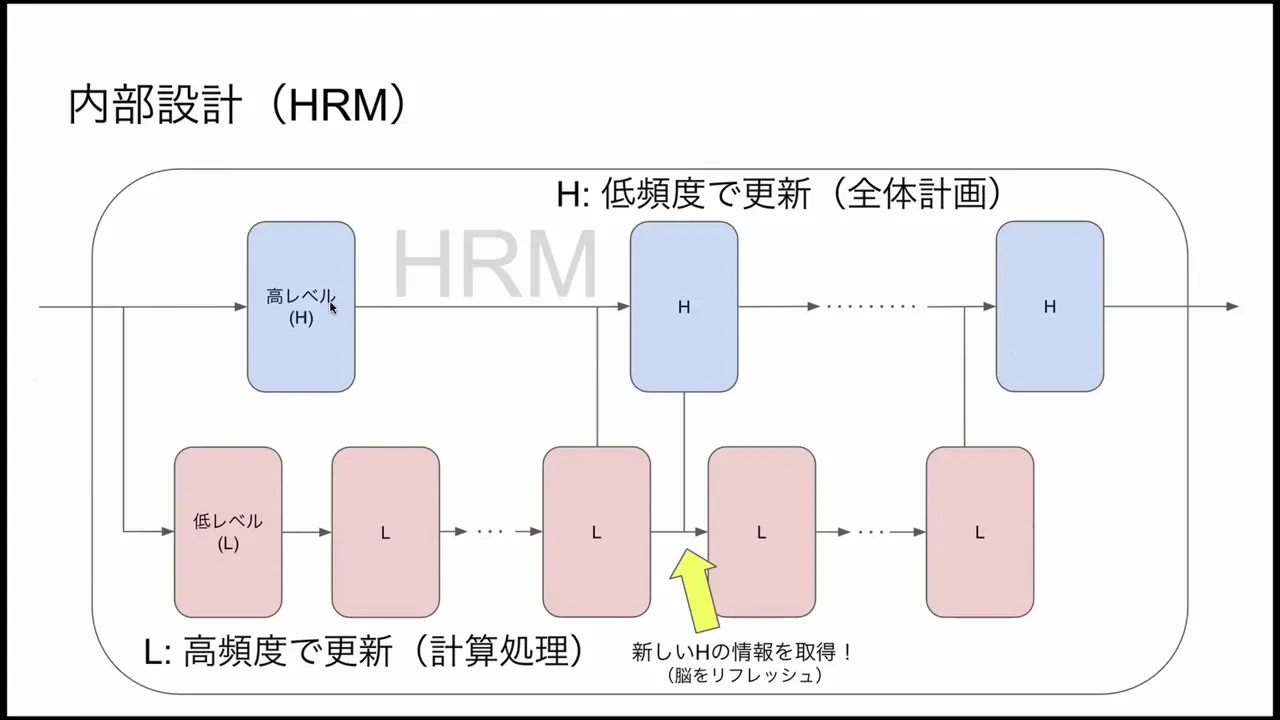
Two-Tier Hierarchy: High-Level (H) and Low-Level (L)
HRM divides computation into two distinct components:
- Low-Level (L): fast-updating units that handle fine-grained computation, such as local inference, sensory-like updates, or short iterative transforms. L is where the majority of rapid internal iteration happens.
- High-Level (H): slow-updating units that maintain global context, planning, and abstract hypotheses. H produces higher-order directives or summaries that guide L’s processing.
Each input is first embedded into a latent vector space (the same general idea as transformer embeddings), and then the HRM performs iterative loops where L updates frequently and H updates less frequently. That repeated looping produces effective depth: by letting L iterate many times between H updates, the HRM gains multi-step deliberation without deep stacked layers.
Recurrence Instead of Large Stacks
Instead of constructing a tall transformer stack (many layers), HRM treats certain blocks—especially L—as modules that are reused multiple times during a single inference episode. Reusing the same module via iteration approximates deep computation at much lower parameter cost because the same weights are applied repeatedly.
This design resembles traditional recurrent neural networks (RNNs) in its reuse of weights over time, but HRM avoids classic RNN pitfalls by introducing the hierarchical split. Instead of a single monolithic recurrence that stalls (early convergence), HRM’s H periodically refreshes and reshapes L’s search trajectory, enabling continued progress.
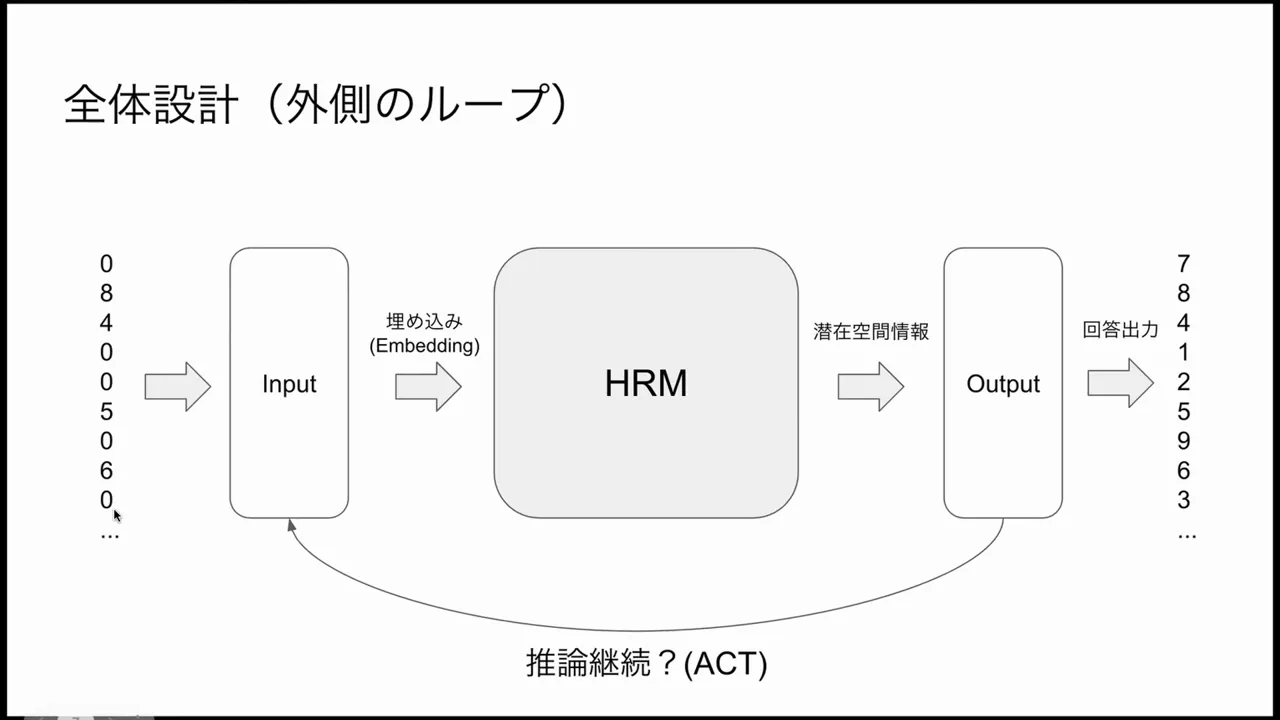
Adaptive Computation (ACT)
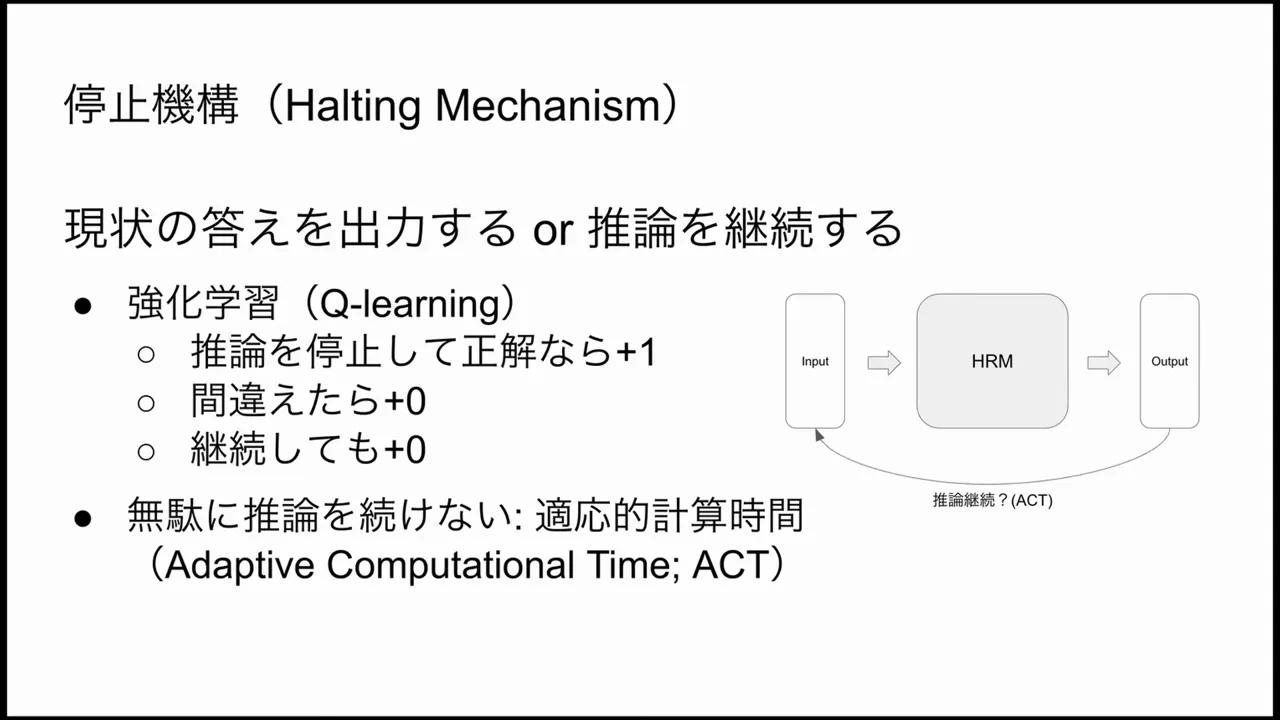
HRM does not use a fixed number of L updates for every input. Instead it uses an adaptive mechanism—Adaptive Computational Time (ACT)—to determine how many iterations are needed. During inference the system can decide to stop iterating and output an answer or keep thinking and run more L cycles. This dynamic allocation prevents wasting computation on easy inputs and applies more thinking to hard ones.
Training Innovations: How HRM Learns Long Reasoning Traces
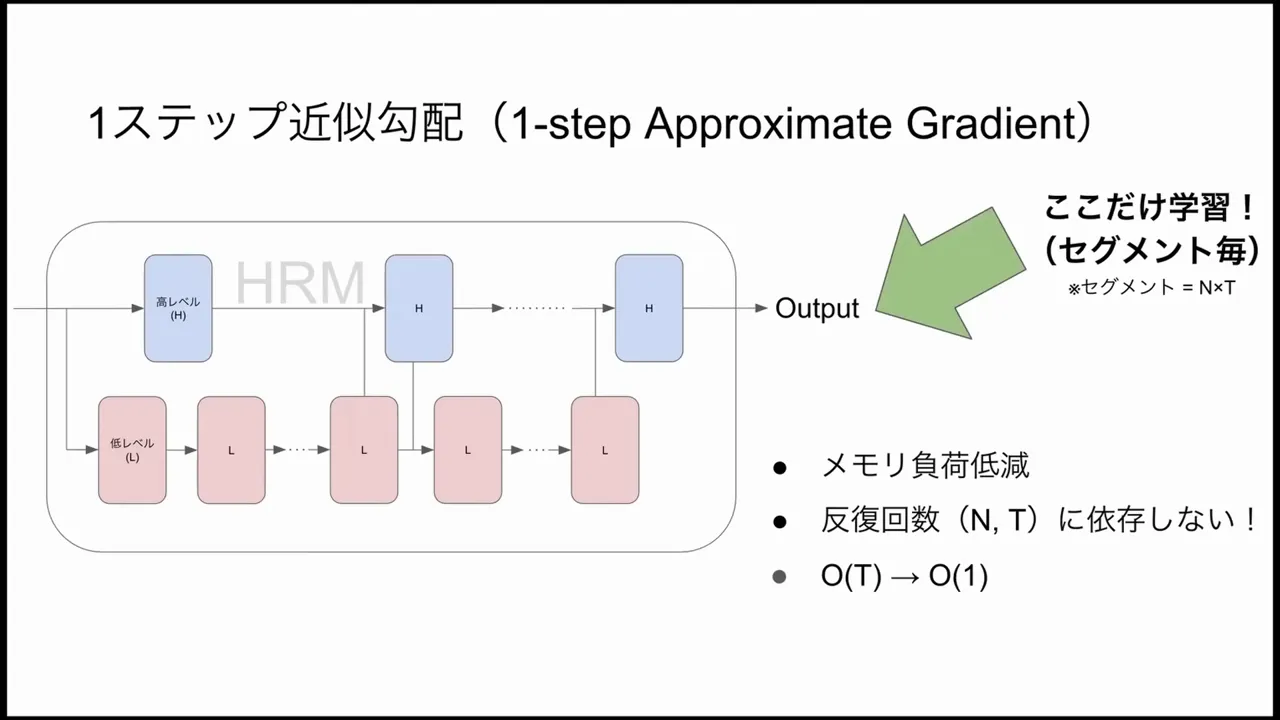
Iterating many times within a single forward pass creates a challenge for learning: the straightforward backpropagation-through-time (BPTT) over many iterative steps grows computation and memory costs linearly with the number of steps. HRM adopts several key strategies to keep training tractable.
Segmentation and One-Step Approximate Gradient
The model divides an episode of thought into segments. Instead of backpropagating through every intermediate update across potentially dozens of L iterations, HRM uses a “one-step approximate gradient” per segment. Concretely, HRM:
- Runs a segment consisting of multiple iterative updates (L updates and possibly an H update),
- At segment end, compares the final latent output against the supervised target or reward,
- Performs a gradient update based on this segment-level error rather than accumulating gradients across every single internal time step.
This reduces memory usage and computation dependency on iteration count: complexity per segment is effectively O(1) with respect to the number of inner iterations. HRM therefore makes long deliberations feasible during training and inference without exploding GPU memory demands.
Memory Updates: Separate H and L Memory
HRM maintains separate latent states or memories for H and L. L updates occur quickly and are saved during iteration; after a few L cycles, the resulting state is passed up to H which may update its slower memory. At training time these H and L memories are treated separately so that updates are efficient and targeted. The architecture copies or splits initial latent representations into Z_H and Z_L, updates Z_L many times, then occasionally refreshes Z_H using aggregated information.
Keeping H and L memories distinct also helps stabilize learning and prevents the rapid iterations in L from causing H’s representation to collapse prematurely.
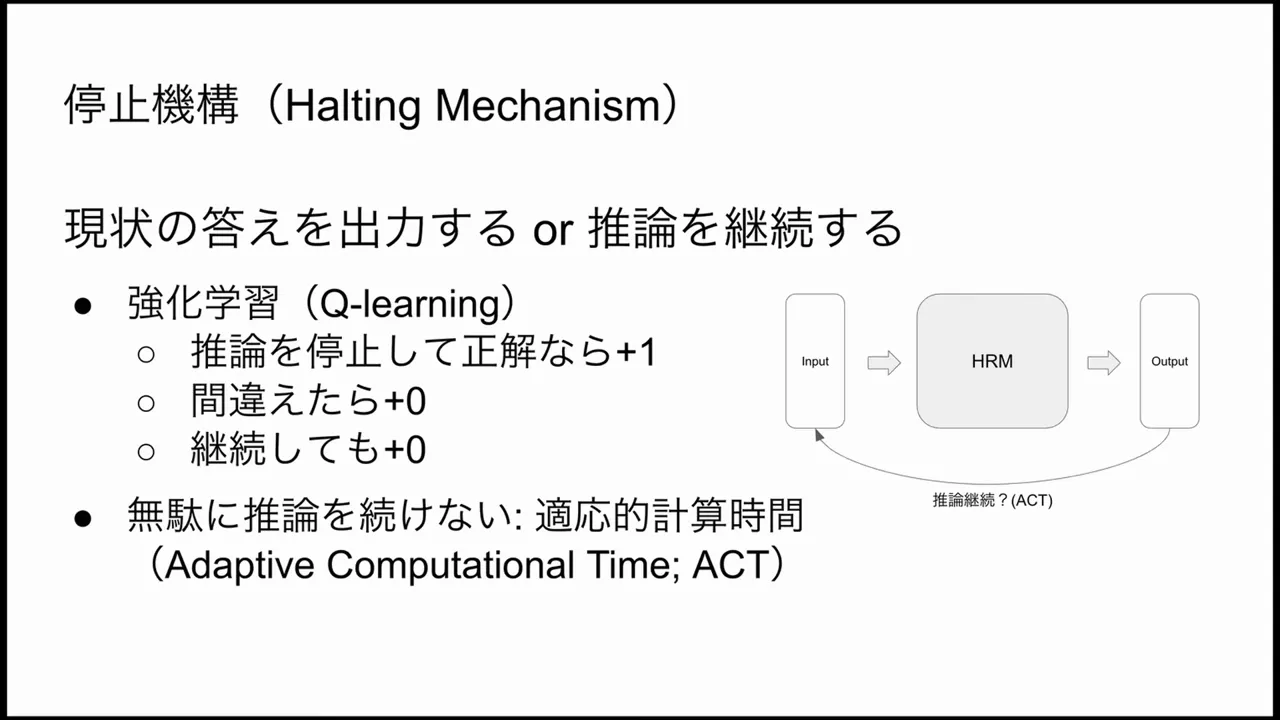
Halting & Decision Mechanism: When to Stop Thinking
One practical question for any iterative reasoning system is when to stop. HRM uses a halting mechanism that decides whether to output a result or continue iterating. This decision is learned through a reinforcement learning-style procedure inspired by Q-learning.
- If the model decides to halt and the answer is correct, it receives positive feedback (reward). If incorrect, it receives no reward or a negative signal.
- Over training episodes, the halting policy learns when continued thinking provides a high expected improvement in final reward vs. the cost (computation/time) of thinking more.
This approach effectively implements ACT in a learned, data-driven manner—hard problems tend to trigger more iterations because the learned halting policy observed that further thinking improves reward, while easy problems halt early.
Why HRM Improves Reasoning: Depth, Avoiding RNN Collapse, and Hierarchical Refresh
At its core, HRM is an architectural answer to the observation that deeper computation tends to improve reasoning capacity, but stacking many parameters is expensive and not always the most efficient route. HRM obtains depth via iteration and avoids the stagnation problems of single-layer recurrence by adding a slower-refreshing hierarchical supervisor.
Depth by Iteration
Every pass where L is applied repeatedly approximates a deeper computation. With N L-iterations, the effective depth is proportional to N even though the parameter count is fixed. This lets a small parameter footprint emulate complex multi-step reasoning by simply reusing weights multiple times.
Avoiding RNN Early Convergence
Standard RNNs can converge early: repeated application of the same function eventually leads to a fixed point that no longer improves the representation. That is why simple recurrence alone can’t keep pushing toward a better solution indefinitely.
HRM avoids this by using H as a periodic “refresh.” When L appears to have converged locally, H updates and provides new top-down guidance that changes the optimization landscape L is operating in. That prevents L from being stuck in local fixed points and enables progressive refinement across multiple cycles of “converge then refresh.”
Emergent Role Differentiation
While HRM is architected with H and L having different update frequencies and roles, the emergent behavior observed in experiments is that H tends to learn abstract, global, exploratory representations and L focuses on localized, execution-level computations. That spontaneous role differentiation mirrors the separation between higher-order planning and reactive computation that cognitive scientists often attribute to biological systems.
Biological Inspirations: STDP and Mixed Selectivity
One of HRM’s most discussed aspects is its conceptual link to features of biological brains. The designers cited two neural phenomena: spike-timing dependent plasticity (STDP) and mixed selectivity / high-dimensional integrative representations.
STDP Analogy
STDP is a synaptic learning rule observed in biological neurons: the relative timing of spikes (pre- and post-synaptic firing) determines whether synaptic strength increases or decreases. Essentially, the timing and frequency of interactions between neurons governs whether learning occurs.
HRM echoes this idea by having processing occur at different frequencies. Low-level updates act at a higher frequency (many quick iterations), while high-level updates act at a lower frequency (occasional refreshes). Learning is more effective when updates align in the right way—analogous to spike timing producing plasticity. This multi-frequency processing can accelerate learning and selectively consolidate knowledge in the right circumstances.
Mixed Selectivity and High-Level Integration
Another property of biological neocortex is mixed selectivity: neurons respond to complex combinations of inputs rather than simple features. That capacity yields high-dimensional representations that can generalize across many tasks. HRM’s high-level module exhibits behavior reminiscent of mixed selectivity: as tasks get more difficult, H allocates more representational “dimensions” or expressive capacity. For easy tasks, H uses a smaller portion of its representational space. This adaptive use of dimensions mirrors how biological systems recruit additional resources for more complex tasks.
These parallels are not proofs that HRM is implementing human-like cognition, but they provide interpretive frameworks that help explain why hierarchical, multi-frequency architectures are effective for complex reasoning.
Experimental Results: Puzzles, Mazes, ARC, and Parameter Efficiency
HRM was evaluated on several benchmarks often used to assess reasoning capabilities. The highlights include:
- Grid number puzzles (Sudoku-like readout): These tasks require scanning an ordered grid and producing a transformed output. HRM showed good performance here while many large pre-trained LLMs failed without specialized fine-tuning.
- Maze navigation: Given a top-down grid with a start and goal, can the model determine a valid path? HRM performed well, benefiting from internal iterative simulation rather than language-based reasoning.
- IQ-style puzzles and ARC-like tasks: HRM showed notable gains on some tasks, but results were mixed on broader ARC (Abstraction and Reasoning Corpus) style tests and certain IQ subtests.
Parameter Efficiency
Perhaps the most jaw-dropping claim is the scale: HRM variants that solved these tasks had parameter counts in the tens of millions, an order of magnitude smaller than many LLMs used as baselines. A quoted number from the presentation indicated roughly 17 million parameters for an HRM variant versus many billions or trillions for large-scale models—a ~4,000x–50,000x difference depending on which scale you compare.
Why this matters: it suggests that certain structured reasoning problems can be solved with careful architecture and training tricks rather than simply scaling up parameters. Compact, efficient models mean lower compute cost, easier research experimentation, and the possibility of running on local hardware.
Limitations and Open Questions
HRM is promising but far from a finished solution to general intelligence. The presentation emphasized several important caveats.
Generalization and Pretraining
Most HRM evaluations reported in the paper used task-specific training: the model was trained on many examples of the same type of puzzle or maze before being tested. That raises a central question: how well does HRM generalize to tasks outside its training distribution, and can it scale to open-domain reasoning using large-scale unsupervised pretraining like transformers? Initial results do not yet demonstrate the kind of general natural language understanding and broad zero-shot performance LLMs deliver.
In short: HRM might be extremely efficient at a particular class of structured reasoning tasks when trained with lots of in-distribution examples, but the jury is still out on whether the same tiny architecture can serve as a general-purpose model of language, vision, and world knowledge.
ARC & IQ Tests: Not Uniformly Better
While HRM made big strides on grid and maze tasks, arc-like tasks and some IQ metrics did not see equivalent improvements. This suggests that simply adding iterative depth is not a universal fix: some problems require other forms of abstraction, richer modalities, or training methodologies that HRM’s current training recipe does not capture well.
Segmentation Approximation Shortcomings
The one-step approximate gradient and segmentation trick avoids backpropagation through all inner steps, but it also sacrifices learning signals for the intermediate steps. If crucial learning occurs during intermediate transformations, the approximation can miss it. That could help explain why some tasks that depend heavily on intermediate manipulations (rather than final outcomes) don’t benefit as much from HRM’s simplified gradient approach.
Language and Output Modalities
HRM’s publicly presented implementations were encoder-focused and not designed out-of-the-box to be autoregressive text generators. Transformer decoders specialized for language produce fluent text by design; encoder-only architectures (like BERT-style) are not the same. So HRM is not yet a substitute for LLMs that must write coherent paragraphs, hold long conversations, or access massive world knowledge. Integrating HRM reasoning modules into larger language-capable systems is a plausible path, but not trivial.
Practical Implications: Small Models, Big Possibilities
HRM’s biggest practical takeaway is encouragement: not every progress story in AI needs to be a top-down arms race of ever-larger transformer stacks. Architectural ideas, biologically inspired structuring, and optimization strategies can yield dramatic efficiency gains for specific problem classes.
- Local & edge deployment: Compact HRM variants that perform complex structured reasoning could be deployed on devices where running a giant LLM is infeasible.
- Research accessibility: Smaller models allow universities and startups to experiment with cutting-edge reasoning algorithms without massive compute budgets.
- Hybrid systems: Combining HRM as a dedicated reasoning module with a large pretrained LLM for language/knowledge access could offer the best of both worlds: fluent output plus deep internal deliberation on complex subproblems.
Potential Future Directions and Hybrids
Given HRM’s strengths and limits, several development paths seem plausible:
- HRM as a reasoning coprocessor: LLMs could delegate heavy multi-step reasoning to an HRM-like module, passing latent representations rather than language prompts. The LLM would provide context and interpret results for human-facing outputs.
- Multimodal HRM: Extend HRM’s encoder-based design to include vision and sensor inputs, enabling the iterative latent deliberation to operate directly over pixel or spatial inputs—a natural fit for tasks like physical planning or visual puzzle solving.
- Scale experiments: Investigate whether HRM principles scale up: does a bigger H/L architecture plus iterative cycles yield further improvements on broad tasks while staying more efficient than a huge transformer stack?
- Better hybrid gradients: Improve approximations so that important intermediate learning is not lost while maintaining tractability. This could bring the best of both worlds: deep internal learning signals without prohibitive memory costs.
Frequently Asked Clarifications
Is HRM the same as a transformer?
No. HRM is not a single transformer module. Internally it uses transformer-style encoders for embedding and certain computations, but the overall HRM architecture is a hierarchical recurrent system built on top of (or wrapping) transformer blocks. Conceptually it is a next-generation structure that mixes recurrence, hierarchy, and attention.
Can HRM replace an LLM for language tasks?
Not yet. HRM prototypes have not demonstrated the broad language understanding, long-range world knowledge, or fluent generation typical of LLMs trained on colossal corpora. HRM excels on structured reasoning tasks for which the architecture aligns with the problem, but it is not currently a drop-in replacement for general-purpose language models.
Why does HRM sometimes still underperform on ARC and some IQ tests?
There are multiple reasons. Some tasks require learning rich intermediate transformations that the segmentation approximation may not capture. Some tasks benefit from large amounts of world knowledge or cross-modal representations that HRM hasn’t been trained on. Additionally, not all problems benefit linearly from added deliberation—some need different representations or an alternate training objective.
Key Quotes and Takeaways
“Small models can be surprisingly capable when their architecture lets them think in the right way—by iterating selectively, refreshing higher-level plans, and learning when to stop.” — summary interpretation from Singular Radio’s HRM discussion.
That encapsulates the spirit of HRM: the architecture treats thinking as a resource to be scheduled, shaped, and refreshed, rather than an automatic consequence of stacking more layers.
Conclusion: Where HRM Fits in the Trajectory Toward Better Reasoners
HRM represents an exciting architectural idea: instead of scaling purely by parameter count, it scales reasoning capability by allocating computation over time in a hierarchical, adaptive manner. HRM reinvigorates older ideas—recurrence, hierarchical control, and adaptive computation—and combines them with modern attention-based modules to create a compact but effective reasoning engine for structured tasks.
Importantly, HRM is not yet AGI nor a universal replacement for transformer-based LLMs. Rather, it is a compelling proof-of-concept: for many problem classes, thinking more (iteration) and thinking differently (hierarchy + halting) can yield large gains without massive models. The broader research agenda now includes integrating HRM-like reasoning with large pre-trained models, improving its generalization beyond task-specific training, and refining training techniques so intermediate computation is learned precisely.
For practitioners, HRM signals that architectural innovation can still dramatically improve efficiency and capability. For researchers, HRM opens the door to new hybrid systems that combine compact, deliberative modules with large, knowledge-rich language front-ends. For the AI community, HRM is a reminder: progress is not only a question of “bigger” but also “smarter design.”
Final Note
HRM’s results and surrounding discussion highlight the value of revisiting biological principles, computational constraints, and the economics of model design. Whether the HRM approach becomes a component of future state-of-the-art systems or remains a specialized tool for structured reasoning, it has already influenced how researchers and engineers think about depth, iteration, and the efficient allocation of computational thought.