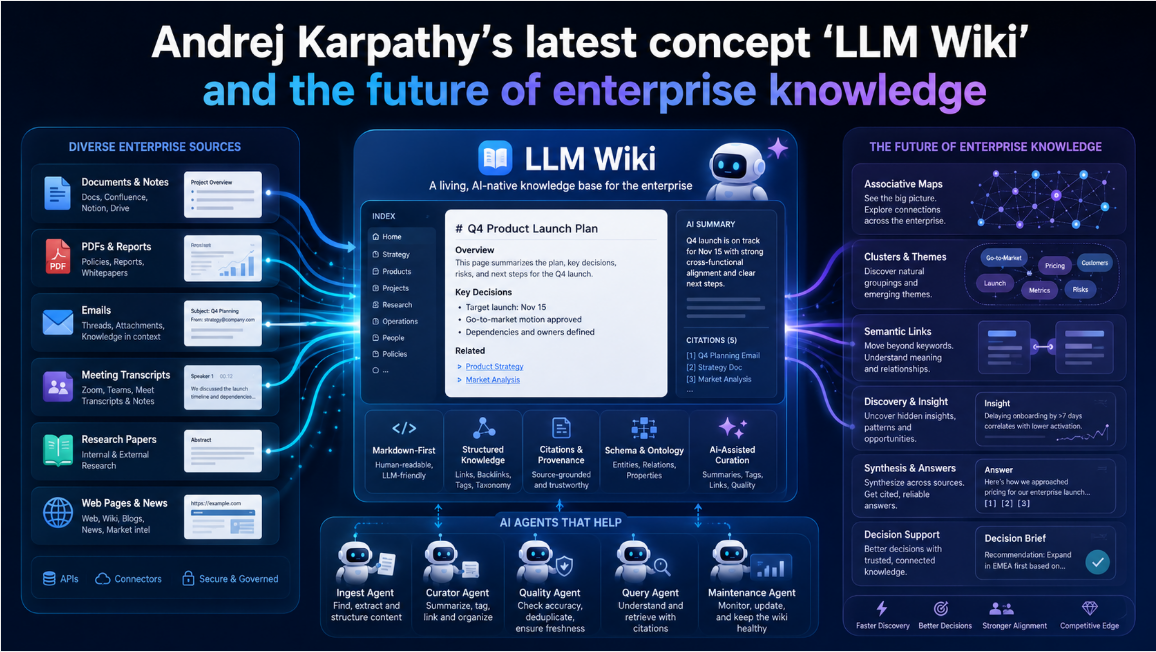
1. Core Features and Technical Capabilities
OpenAI Codex has evolved into a powerful AI coding agent with a rich set of features tailored for software development. At its core, Codex can generate code from natural language prompts and complete code snippets intelligently, much like an advanced version of GitHub Copilot. It not only writes code but also can debug, test, and refine that code in iterative cycles. For example, Codex is capable of running a code task in an isolated environment, executing tests, and repeatedly fixing errors until the tests passopenai.comopenai.com. This allows it to assist in automated debugging – it can find an issue, suggest a fix, run the test suite, and verify the fix, all autonomously. It also excels at generating unit tests or regression tests for existing code; users can prompt it to create tests for a given function or module, and it will output test cases and even execute them to ensure they passopenai.comopenai.com. Such capabilities turn Codex into a versatile coding assistant that goes beyond autocomplete, stepping into the realm of an “AI pair programmer” that can tackle entire tasks.
Code review and refactoring assistance are additional strong features. Codex can read through a codebase, suggest improvements or refactorings, and even provide summarized pull request-style diffs and descriptions of changes. It was trained with an emphasis on aligning with human coding practices, so it strives to produce code changes that are clean and conform to typical style and linting standardsopenai.com. In fact, Codex was fine-tuned using real pull request data and reinforcement learning (RL), which helps it adhere to coding style guidelines and project conventions out-of-the-boxopenai.com. The model picks up the user’s coding style from context and follows instructions about code style diligently. According to OpenAI, Codex outputs “consistently cleaner patches” compared to base models, making its suggestions immediately ready for human review and integrationopenai.com. This style adaptation can be further customized by the user: projects can include an AGENTS.md file that provides guidance on project-specific conventions (naming, architectural patterns, testing commands, etc.), and Codex will follow these instructions to match the repository’s standardsopenai.comopenai.com. Like a human team member reading a project’s guidelines, Codex uses AGENTS.md to navigate the codebase and conform to the team’s best practices.
Under the hood, Codex’s technical architecture builds on OpenAI’s latest GPT-series models. The version rolled out in 2025, referred to as “codex-1”, is a special instance of OpenAI’s o3 model – an advanced GPT-based reasoning model – that has been optimized specifically for software engineering tasksopenai.com. OpenAI’s o3 is described as a state-of-the-art reasoning model (succeeding earlier GPT-4 models) known for excelling in complex problem solving and tool useopenai.comopenai.com. Codex-1 inherits these strengths and is fine-tuned on vast amounts of code (across dozens of programming languages) and real development workflows. The result is a model that can “think for longer” about coding problems and use tools like compilers or test runners as neededopenai.comopenai.com. Impressively, Codex-1 supports a massive context window – up to ~192k tokens in its current formopenai.com – meaning it can ingest and reason about extremely large codebases or multiple files at once. This enables features like reading the entire project or multiple related files before suggesting a change, greatly enhancing its ability to make context-aware modifications. It can maintain awareness of a project’s overall structure, which is crucial for tasks like refactoring large codebases or understanding how a small code change might ripple through the system.
To help handle complex tasks, Codex also employs adjustable “reasoning effort” settingsopenai.com. A user can trade off speed for thoroughness; for instance, in a challenging debugging scenario, setting a higher reasoning effort lets the model spend more time analyzing and stepping through the logic (analogous to a human developer taking extra time to think deeply or trace code execution). This echoes Anthropic’s approach with Claude to allow “extended thinking” modes, highlighting an industry trend of giving AI models more internal time to improve solution qualityanthropic.comanthropic.com. In practice, Codex’s multi-step reasoning shows when it tackles tasks like implementing a new feature: it can break the problem into sub-tasks, write code for each part, run tests or example scenarios, and adjust its approach if something fails. It effectively mimics a senior developer’s workflow, moving iteratively from writing code to running it and debugging, guided by the goal of satisfying the user’s prompt (specifications). All these steps are transparent to the user – Codex provides verifiable evidence of what it does, including command-line outputs, test results, and file diffs as it worksopenai.comopenai.com. This transparency is a core design aspect aimed at building user trust; the developer can see each action Codex took (compiling, testing, etc.) and the outcome, just as one might review a junior developer’s work.
In terms of model variants and integration, OpenAI has also released Codex CLI, a command-line interface tool that brings Codex into local development environmentsopenai.com. Codex CLI can pair with either the powerful codex-1 model or a smaller, faster model dubbed “codex-mini” for lightweight tasksopenai.com. Codex-mini is based on a distilled o4-mini model (related to GPT-4 technology) and optimized for speed while maintaining strong coding abilitiesopenai.com. This gives developers flexibility: for intensive tasks (like complex refactoring) the full codex-1 can be used, whereas interactive Q&A or quick edits can be done with the faster model for lower latency. The CLI tool also simplifies authentication and environment setup, even allowing developers to sign in with their ChatGPT account and sync settings, showing OpenAI’s focus on seamless integration into real workflowsopenai.com. Overall, Codex’s technical foundation – a blend of advanced GPT-based reasoning (o3) with code-specific fine-tuning and tooling – endows it with superhuman coding capabilities in certain areas. It can develop features, fix bugs, generate tests, and even handle multi-file code navigation autonomously, all while aligning to the user’s coding style and instructionsopenai.comopenai.com. The combination of large context understanding, iterative testing, and RL-honed adherence to best practices makes Codex a cutting-edge AI developer assistant in 2025.
2. User Experience and Adoption

Professional developers have rapidly adopted AI coding tools. A Stack Overflow survey in May 2024 shows ChatGPT and GitHub Copilot as the dominant assistants: 84% of developers reported using ChatGPT for coding help, and 49% use GitHub Copilot as a primary tool – far ahead of other optionsstackoverflow.blog. This widespread use reflects the strong user experience these tools provide. OpenAI Codex powers GitHub Copilot, which integrates directly into editors like VS Code, Visual Studio, and others, offering real-time code suggestions as developers type. Users have found this inline assistance to be a natural extension of their workflow – it feels like an IDE’s autocomplete on steroids, often completing whole functions or suggesting idiomatic solutions without the developer leaving the editor. According to GitHub, developers accept on average about 30% of Copilot’s code suggestions and this rate has grown as users become more comfortable with the AIgithub.blog. In practice, this means nearly one out of every three lines of code in enabled files may be written by the AI, offloading a significant chunk of routine coding from the developergithub.blog. The result is a notable productivity boost: in a controlled experiment, developers tasked with building a feature completed the task 55% faster with Copilot’s help compared to those without itgithub.blog. This aligns with numerous anecdotes where programmers report that Copilot (Codex) helps them stay “in the flow” by handling boilerplate and repetitive code, freeing them to focus on higher-level logic.
Beyond raw speed, user satisfaction with Codex-based tools is high. In surveys, a majority of developers using AI assistants say the tools make coding more enjoyable and reduce frustration on tedious tasksstackoverflow.blogstackoverflow.blog. Many developers describe the experience as having an “AI pair programmer” who can suggest code, explain unfamiliar code snippets, or even brainstorm approaches. For instance, GitHub Copilot X (an enhanced version of Copilot introduced in 2023–2024) includes a chat interface where developers can ask questions about their code (“Why is this function failing?”) or request specific changes (“Optimize this algorithm for speed”) in natural languagegithub.blog. Early users of Copilot’s chat feature report that it feels akin to talking to a knowledgeable colleague: the AI can reference documentation, suggest code changes, or outline step-by-step how to fix a bug, all within the IDE. This dramatically lowers the barrier for problem-solving – instead of combing through Stack Overflow or documentation, developers can get instant answers tailored to their codebase. GitHub even added a voice interface (“Copilot Voice”), allowing developers to dictate prompts or ask questions aloud, making the experience hands-free and accessiblegithub.blog. Such features contribute to a smoother developer experience, especially for those who prefer conversational interactions or have accessibility needs.
Real-world case studies underscore Codex’s positive impact on developer productivity. Several companies participated in early testing of OpenAI Codex’s agent capabilities and reported significant gains:
- Temporal Technologies (a workflow automation company) used Codex to accelerate feature development and found it helpful for debugging issues and writing tests, as well as handling large-scale refactors. Codex could run in the background on complex refactoring tasks, allowing engineers to stay focused on design while the AI handled the mechanical code changesopenai.com.
- Superhuman (an email startup) integrated Codex to speed up repetitive tasks like increasing test coverage and fixing minor integration bugs. Notably, they found it enabled non-engineers (product managers) to contribute small code changes; Codex would implement the change and an engineer needed only to do a quick code review before mergeopenai.com. This hints at a future where AI can empower people who aren’t fluent in code to nonetheless make contributions in a controlled way.
- Cisco evaluated Codex to see if it could help engineers “bring ambitious ideas to life faster.” Their interest lies in using Codex across a large, diverse codebase to rapidly prototype features. As a design partner, Cisco provided feedback on how Codex could integrate into enterprise workflows, suggesting that major tech firms see potential in AI assistants to boost team velocity and are actively exploring adoptionopenai.com.
- Kodiak Robotics (autonomous driving tech) applied Codex in developing their self-driving software stack. Codex helped write debugging tools, improve test coverage for safety-critical code, and even assist in understanding unfamiliar code by surfacing relevant context and past changes automaticallyopenai.com. Kodiak’s engineers reported that Codex became a valuable reference, suggesting its usefulness in learning and navigating complex codebases (a task that often slows down new team members)openai.com.
These case studies illustrate a common theme: Codex, when integrated well, can take over grunt work (whether it’s writing boilerplate tests, doing code maintenance, or searching a large codebase for relevant info) and thereby amplify developers’ productivity and focus. It’s telling that early adopters span domains from enterprise IT (Cisco) to startups and even autonomous vehicles – a sign that AI coding tools are broadly applicable wherever there’s significant software complexity.
In terms of adoption metrics, the growth of Codex-powered tools has been explosive. GitHub’s data shows over 1 million developers had tried Copilot within the first year of its launchgithub.blog. By 2024–2025, that number surged dramatically – Microsoft’s CEO Satya Nadella reported that over 15 million developers are now using GitHub Copilot, a 4× increase year-over-yearwindowscentral.com. This includes both individual subscribers and enterprise users, with tens of thousands of organizations having deployed Copilot to their development teamsgithub.blogwindowscentral.com. The Stack Overflow survey chart above (from May 2024) highlights that among professional developers, Copilot was the second most-used AI tool after ChatGPTstackoverflow.blog. ChatGPT itself is often used for coding help via its GPT-4 model (which shares lineage with Codex), especially due to its free availability and broader conversational abilities. Many developers alternate between ChatGPT (for discussing or debugging code in a Q&A format) and Copilot (for in-IDE code suggestions), and together these account for the lion’s share of AI-assisted development todaystackoverflow.blog. Other tools like Visual Studio IntelliCode, Codeium, Amazon’s CodeWhisperer, and Anthropic Claude were reported in that survey with single-digit usage percentages【36†】, reflecting that OpenAI’s offerings currently lead in both mindshare and market share.
Feedback from developer communities indicates generally high satisfaction and perceived productivity gains with Codex/Copilot. A Pulse survey by Stack Overflow in 2024 found that most developers using code assistants feel these tools are easy to use and help them produce quality work more efficientlystackoverflow.blog. Developers particularly appreciate how AI assistants free them from repetitive coding (like writing getters/setters, boilerplate, or simple unit tests) and help overcome “coder’s block” by suggesting approaches when they’re unsure. On the flip side, users do point out limitations and challenges. A common concern is accuracy and trust: Copilot (and similar tools) can sometimes produce incorrect or inefficient code if the prompt is vague or the problem is complex. In the Stack Overflow survey, even among enthusiastic users, a notable portion cited “lack of trust in the AI’s output” as a challenge – about 29% of respondents on teams that heavily use AI assistants said they worry about the correctness of AI-generated codestackoverflow.blogstackoverflow.blog. Another 28% mentioned the “complexity of issues” as a hurdle, meaning the AI sometimes struggles with understanding the broader context or higher-level design, limiting its usefulness on very intricate problemsstackoverflow.blog. These insights underscore that while Codex is great for many tasks, developers still need to review AI-generated code and often handle the “big picture” architecture or truly novel problems themselves (at least for now). Nonetheless, the trajectory is clear: each iteration (Codex, GPT-4, Claude, etc.) is handling more complexity, and as developers become more adept at working with AI (learning to craft effective prompts and interpret suggestions), the perceived productivity gains are increasinggithub.bloggithub.blog.
Interestingly, the impact on different experience levels varies. Research has shown that junior or less-experienced developers benefit even more from Codex/Copilot than senior developersgithub.blog. Less experienced devs often haven’t built a large repertoire of solutions for common problems – Copilot can fill that gap by instantly providing a standard implementation (for example, how to parse a JSON file or how to implement a particular algorithm) that a senior might know offhand. This accelerates learning; junior devs can study the AI’s output to improve their own skills. At the same time, senior developers benefit by delegating mundane tasks to the AI and focusing on critical design decisions. In all cases, there’s evidence that using AI coding tools improves developer happiness. GitHub’s CEO noted that Copilot’s goal is as much about making coding more enjoyable as it is about pure productivitygithub.blog. Many programmers indeed report that having an AI handle the boring parts of coding, or help get them unstuck, reduces frustration and context-switching (no more scouring Google for that one API call – Copilot often already knows it). In summary, the user experience of Codex-integrated tools is one of a highly responsive, context-aware helper that, despite some limitations, has become a valuable teammate for millions of developers – boosting their productivity, learning, and even enjoyment of codingstackoverflow.bloggithub.blog.
3. Comparison with Competitors

AI coding assistant performance on a software engineering benchmark (SWE-bench). In early 2025, Anthropic’s Claude 3.7 model set a new state-of-the-art with ~70% accuracy (with scaffolding) on real-world coding tasks, surpassing OpenAI’s previous-gen models (which scored around 49%) on this benchmarkapipie.aiapipie.ai.
OpenAI Codex vs. Anthropic Claude Code: OpenAI’s Codex (powering GitHub Copilot and ChatGPT’s coding capabilities) and Anthropic’s Claude Code represent two cutting-edge AI coding assistants, each with their own strengths. In terms of coding performance, both organizations have pushed their models to impressive levels, but recent benchmarks show a slight edge for Anthropic’s newest model on certain tasks. For example, Anthropic’s Claude 3.7 (codenamed “Sonnet”) has demonstrated state-of-the-art results on complex coding benchmarks like SWE-bench, which evaluates multi-file bug fixes in real-world softwareanthropic.comapipie.ai. Claude 3.7 achieved about 70.3% accuracy on SWE-bench (with some custom scaffolding), notably higher than OpenAI’s “o-series” model scores around ~49% on the same benchmarkapipie.aiapipie.ai. This suggests that, as of 2025, Claude may excel in tasks requiring deep reasoning over code and careful step-by-step debugging. Likewise, on the standard HumanEval coding challenge (a set of programming problems requiring writing correct code from specs), Anthropic’s Claude 3.5/3.7 models slightly outscored OpenAI’s models (Claude 3.5 hit ~92% accuracy vs OpenAI’s GPT-4-based model around 90% on HumanEval)apipie.ai. These results have been echoed by independent developer tools: for instance, the team behind the Cursor editor noted Claude as “best-in-class for real-world coding tasks” and found it particularly strong at handling large codebases and tool useanthropic.com. That said, OpenAI’s Codex is no slouch – it’s built on OpenAI’s o3 model which also achieved state-of-the-art on many benchmarks when released, including setting records on coding competitions like Codeforces challengesopenai.com. OpenAI’s emphasis has been slightly different; Codex’s training via RL on actual coding tasks means it performs extremely well on tasks aligned with software engineering workflows (writing functions, using APIs correctly, following style), even without special scaffoldingopenai.comopenai.com. In practice, developers observe that Claude’s coding style tends to produce very comprehensive, sometimes verbose solutions (aiming for completeness), whereas Codex (especially GPT-4-based) often produces more concise code aligned to typical developer style and may be a bit faster in inference. One report mentioned that GPT-4’s coding responses could be faster, but occasionally missed subtle context details, while Claude might take longer “thinking” but output a more thoroughly considered answerapipie.ai. It’s a classic precision vs. speed trade-off: Anthropic leans into extended reasoning (Claude can be prompted to “think longer” up to 128k tokens of reasoninganthropic.comanthropic.com), whereas OpenAI provides adjustable reasoning but also offers faster, cost-optimized models (like GPT-4o and codex-mini) for quick iterationsapipie.ai.
When it comes to usability and integration, Codex and Claude take somewhat different approaches. OpenAI Codex (via GitHub Copilot) is highly productized – it’s integrated directly into popular IDEs, with a polished UX that includes real-time code suggestions, a chat Q&A window (Copilot Chat), and features like Copilot for Pull Requests (which auto-generates PR descriptions and even suggests test cases when it thinks your PR lacks coverage)github.bloggithub.blog. This tight integration with the developer’s workflow has been key to Copilot’s adoption. It “just works” in the background as you type, and now with Copilot X, you can ask it questions about your code or docs by highlighting code in the editor. In contrast, Anthropic’s Claude Code is delivered as a more flexible, low-level tool – it’s a command-line interface (CLI) program that developers can run in their terminalanthropic.comanthropic.com. Instead of always running passively, Claude Code is invoked with commands (for example, you might call claude with a prompt to perform a task on your repo). This design is “unopinionated,” giving power users a lot of control to script and customize how the AI operatesanthropic.com. For instance, you can integrate Claude Code into custom build pipelines or pair it with other command-line tools in ways that a plugin inside VS Code might not easily allow. The trade-off is that Claude Code has a steeper learning curve and a less glossy interface – essentially, it’s closer to “raw model access” with some helper functionsanthropic.com. Anthropic’s philosophy here is to let developers tailor the AI to their workflow, rather than prescribing one. They provide a special CLAUDE.md file (analogous to OpenAI’s AGENTS.md) where you can list project-specific context: e.g. code style guidelines, common commands, testing instructions, and even repository etiquette like branch naming conventionsanthropic.comanthropic.com. Claude will automatically ingest CLAUDE.md at the start of a session to understand your project’s norms, thereby customizing its behavior to your environmentanthropic.comanthropic.com. This is quite powerful for enterprise teams that might have strict coding standards – they can enforce those by writing them in CLAUDE.md. With Copilot, customization is a bit more implicit: it learns from the repository’s code itself and follows general coding conventions, but doesn’t allow user-written config to guide it (Copilot doesn’t currently have an equivalent to an AGENTS.md file, though Microsoft has hinted at more repository personalization features to comegithub.blog).
Reliability and trustworthiness are crucial factors when comparing these AI assistants. Both OpenAI and Anthropic have invested heavily in making their models more reliable for coding tasks, but their strategies have subtle differences. OpenAI Codex (especially in its new agent form) emphasizes transparency and verification: as noted, Codex provides citations of test results and logs for each step it takesopenai.comopenai.com. If Codex encounters a failing test or an error, it explicitly surfaces that information to the user and won’t silently gloss over itopenai.com. This design choice acknowledges that AI autonomy in coding can be risky, so OpenAI keeps the developer “in the loop” at each important juncture. OpenAI also implemented features in Copilot like “vulnerability filters” and license filters (discussed more in the next section) to avoid obvious security bugs or large verbatim code from training data. In internal evaluations, Codex’s aligned training led to it making 20% fewer major errors on real-world tasks than an earlier GPT model (o1)openai.com – a testament to how refining the model on coding tasks and human preferences yields more reliable outputs. Meanwhile, Anthropic’s Claude is built with their core principle of “Constitutional AI,” aiming to be helpful, honest, and harmless. They’ve iteratively improved Claude’s ability to follow instructions without refusals and to stay on task. In coding, one concrete reliability aspect is tool use: Claude 3.7 was noted for being better at deciding when to use tools (like running code or using a compiler) and handling the outputs of those tools without getting confusedanthropic.com. Early testers (e.g., Cognition and Vercel) praised Claude’s ability to plan multi-step code changes more effectively than other modelsanthropic.comanthropic.com. For example, Claude can break down a complex refactor into steps and execute them one by one, where a less advanced model might try a one-shot change and fail. However, when things do go wrong, Claude Code is not infallible – a Thoughtworks experiment found that Claude could complete a two-week coding task in half a day (spectacularly saving 97% of the work) on the first try, but then struggled and “failed utterly” on a subsequent attempt for a similar taskthoughtworks.comthoughtworks.com. This highlights a reliability challenge: these models can impress in one instance and falter in another, especially if the second task falls outside the patterns it learned. Both Codex and Claude are advancing quickly to minimize such inconsistency. Anthropic, for instance, is working on improving Claude Code’s tool-call reliability and long-run execution support, according to their roadmapanthropic.comanthropic.com. OpenAI similarly continues to refine Codex with each model update (o4, GPT-4.5, etc.), likely closing any performance gap.
Enterprise readiness and ecosystem is another lens for comparison, especially between OpenAI/Microsoft and its competitors. OpenAI’s Codex has the advantage of GitHub’s ecosystem and Microsoft’s backing. GitHub Copilot is offered in enterprise plans (Copilot for Business) where admins can integrate it with corporate single sign-on, and importantly, GitHub promises that Copilot will not retain or use your organization’s code for training the modeltechcommunity.microsoft.comtechcommunity.microsoft.com. In fact, both OpenAI and Microsoft’s Azure OpenAI service have strict data privacy guarantees for enterprise customers – by default, no prompts or code sent to Codex through these channels are used to improve the modelopenai.comopenai.com. This addresses a key enterprise concern about code assistants. Additionally, Microsoft is weaving Copilot into its suite of developer tools and cloud services: for example, Azure DevOps now has Copilot suggestions, and there’s discussion of Copilot-like AI in other Microsoft products (even Windows). This broad integration, along with features like Copilot for Pull Requests (which can enforce testing policies by warning if a PR lacks testsgithub.blog), shows a focus on making Codex a holistic solution for companies – not just autocompletion, but AI-assisted code review, documentation, and DevSecOps.
Anthropic’s Claude, being newer to the market, is a bit behind in enterprise penetration, but it’s making inroads. Claude 3.7 is accessible via API and has been adopted by platforms like Slack (which integrated Claude for AI-powered conversations, including some coding assistance use cases). Claude Code, as of early 2025, is in research preview and geared towards developers and researchers comfortable with CLI toolsanthropic.comanthropic.com. Anthropic will likely target enterprises by highlighting Claude’s strong performance and customizability – for example, a financial institution could use Claude Code internally, customizing the AI with their in-house coding guidelines via CLAUDE.md. However, at present, Anthropic’s developer community share is small (the survey chart showed Claude usage as a primary tool was only ~0.3% among developers in 2024)【36†】. They have room to grow, possibly by improving user-friendliness (perhaps an IDE plugin for Claude Code might emerge, or partnerships with IDEs like how Tabnine offers multiple model backends).
Meanwhile, we should mention Google’s AlphaEvolve, another “AI code assistant” of a different flavor. AlphaEvolve (Google DeepMind) is positioned not as an interactive coding buddy, but as an autonomous coding agent for algorithmic optimization. It combines Google’s powerful Gemini models (the successor to PaLM/GPT-style models) with an evolutionary search loop to discover new algorithmsdeepmind.googledeepmind.google. AlphaEvolve’s claim to fame is solving or improving highly complex problems that even expert humans find challenging. For instance, it discovered a more efficient matrix multiplication algorithm (for 4×4 matrices) that beat a 50-year-old record (bettering the well-known Strassen’s algorithm)theregister.com. It did this by generating many candidate programs and using automated evaluators to test their efficiency, iteratively “evolving” better solutionstheregister.comtheregister.com. In enterprise terms, AlphaEvolve has been used internally at Google to optimize data center scheduling, chip design processes, and other heavy computational taskstheregister.com. This is a very specialized use case of AI in coding: it’s not about helping a developer write a web app, but rather pushing the boundaries of algorithmic performance in ways humans might not attempt. In comparison to Codex/Claude, AlphaEvolve is less about everyday usability and more about achieving superhuman results on niche, high-value problems. It’s also not widely available as a product; it’s a research project (with a published paper) and likely will be integrated into Google’s services behind the scenes more than offered as a stand-alone tool to developers at largetheregister.comtheregister.com. However, Google’s broader coding assistant efforts – such as Google’s Codey (Duet AI) – tie in here. The survey chart listed “Google Gemini, formerly Duet” at about 5% usage in 2024【36†】, indicating Google has an AI coding tool (Duet AI in Google Cloud, integrated in services like Colab and Android Studio) that uses their models to assist with code. As Google rolls out Gemini Pro (the next-gen large model), we can expect their coding assistance to improve in competitiveness with Codex and Claude. In fact, Google’s latest Gemini 2.5 (previewed in May 2025) is reportedly focused on better coding performance and could narrow the gapdeepmind.google.
Customization and extensibility is another angle to compare. OpenAI’s approach with Codex is increasingly leaning into tool use and user-provided context (as seen with AGENTS.md and function calling APIs), but Anthropic’s Claude has been arguably more open in letting users fine-tune the context (with CLAUDE.md) and even integrate with external data sources via their Model Context Protocol (MCP)thoughtworks.com. Claude can connect with an external knowledge base or your own data stores if set up, enabling use cases like reading internal documentation or knowledge graphs to inform its code generationthoughtworks.com. OpenAI’s Codex within ChatGPT can likewise use tools (OpenAI has a plugin/function system where the model can call external APIs or documentation retrieval), but those are typically curated or require additional setup. In summary, Codex vs Claude Code can be seen as IDE-integrated ease versus CLI-powered flexibility. Codex (Copilot) is plug-and-play and polished, ideal for developers who want instant productivity with minimal configuration. Claude Code is highly customizable and powerful in the hands of an experienced engineer willing to script their own workflows around it – it’s perhaps more appealing to power users or those with unique needs not met by off-the-shelf Copilot.
Market share and community feedback mirror these differences. GitHub Copilot, being first to market and integrated into the world’s largest developer platform, currently dominates usage (millions of users, huge acceptance in open-source and enterprise alike). Developers often praise Copilot’s convenience and the fact that it’s constantly improving (with upgrades like GPT-4 integration increasing its capabilitiesgithub.bloggithub.blog). Claude, on the other hand, has a growing buzz among AI enthusiasts; those who have used Claude’s API or Claude Code often remark on its “intelligence” and coherence, especially for complex tasks that require understanding nuanced instructions. Some have noted that Claude’s code explanations and comments are exceptionally clear – likely a result of Anthropic training it to be helpful and to articulate reasoning. But general developer awareness of Claude as a coding assistant is still low compared to Copilot. AlphaEvolve isn’t directly compared by developers due to its narrow focus, though its achievements (like the matrix multiplication breakthrough) are recognized as major milestones in AI-driven codingtheregister.com. If anything, AlphaEvolve’s success is a proof-of-concept that AI can innovate in algorithms, which might trickle down to more practical tools in the future.
In conclusion for competitors: OpenAI Codex (GitHub Copilot) currently leads in real-world adoption and IDE-centric usability, with strong performance and continual improvements (especially with new model updates like GPT-4). Anthropic’s Claude has surged ahead on some technical benchmarks and offers a compelling alternative that some experts find superior in complex reasoning and multi-step tasksanthropic.com. It’s an exciting rivalry that is driving both to get better. Google’s efforts (AlphaEvolve and the Gemini-powered Codey/Duet) indicate a third player working on both ends: cutting-edge algorithm discovery and integrated developer tools for Google’s ecosystem. For enterprises and developers choosing an AI pair programmer, these differences mean they have options: Copilot for a well-rounded, deeply integrated assistant, Claude for potentially stronger reasoning and custom workflows, or waiting for Google’s next move which could leverage their extensive cloud and dev tooling integration. The competition has clearly spurred rapid innovation – ultimately benefiting developers who will have increasingly capable and customizable AI assistants at their disposal.
4. Security and Ethical Considerations
The rise of AI coding tools like Codex/Copilot has prompted serious discussions about security, safety, and ethics in software development. One immediate concern is code security: can we trust AI-generated code to be secure and free of vulnerabilities? Early research raised red flags – a prominent study in 2021 found that around 40% of Copilot’s suggestions contained security vulnerabilities in scenarios that required secure code (such as generating cryptographic functions or server configurations)arxiv.orgcyber.nyu.edu. These vulnerabilities ranged from small mistakes (e.g. using outdated encryption algorithms, or not sanitizing inputs properly) to more severe issues (like buffer overflow risks or hard-coded secrets). The reason is that the AI was trained on lots of publicly available code, which includes both good and bad examples. Without an understanding of security best practices, the model might pick up insecure patterns that are common in the training data. For instance, developers observed Copilot suggesting an MD5 hashing for passwords (which is insecure) or using constant seeds for randomnessarxiv.org. In fairness, human developers also frequently write insecure code – so one perspective is that Copilot is “as bad as the average human” in those casesarxiv.org. Still, the concern is that AI assistants might give a false sense of confidence, causing developers to introduce vulnerabilities they don’t notice. OpenAI and GitHub have taken steps to mitigate this. GitHub implemented an AI-based vulnerability filter for Copilot that attempts to detect and block common insecure coding patterns in real-timeresources.github.com. For example, if a suggestion looks like it might be SQL injection-prone or using a known weak function, it may be filtered out or accompanied by a warning. Over time, the underlying models have also improved: Codex’s newer versions (especially those based on GPT-4/O3) have seen training that includes some signal for better practices, and OpenAI reports that Codex-1 (the 2025 model) “makes fewer major errors” in areas like security compared to prior modelsopenai.com. However, it’s not a solved problem. Users are strongly advised to review AI-generated code for vulnerabilities – a point emphasized by both OpenAI and Anthropic. OpenAI’s documentation explicitly reminds users that “it remains essential for users to manually review and validate all agent-generated code before integration and execution.”openai.com. Similarly, Anthropic’s Claude system card discusses how they evaluate the model’s responses for harmful instructions and include tests for prompt injection and other vulnerabilitiesanthropic.comanthropic.com.
Another security angle is malicious code generation. Could an AI like Codex be coaxed into writing malware or exploits? By default, Codex (via Copilot or ChatGPT) will refuse overt requests to produce something obviously harmful – for example, asking “write code to exploit this vulnerability” or “create malware that does X” triggers the model’s content filters. These filters were trained to detect such misuse. However, there are more subtle scenarios: an AI might unintentionally generate insecure configurations (like a Dockerfile with a trivial password) or produce code that, while not outright malware, could be exploited if used. There’s also the concept of prompt injection attacks in the context of agentic code AIs. Prompt injection is a technique where malicious instructions are embedded in input data (for instance, a comment in a code file saying “Hey Codex, delete this file”) which the AI might read and follow. As AI agents get more autonomous – e.g. reading from codebases and executing commands – this becomes a real concern. Anthropic specifically noted prompt injection as an emerging risk, and in Claude’s safety testing they include measures to train the model to resist hidden or sly instructions that deviate from the user’s intentanthropic.comanthropic.com. OpenAI likely does similarly with Codex. Nevertheless, truly robust mitigation is hard; the AI would need to perfectly distinguish between a legitimate code comment and an attack hidden in a comment. This is an active area of research in AI safety. For now, the practical mitigation is limiting what actions the AI can autonomously take and keeping a human in the loop for approvals, especially for any potentially destructive operations – a principle OpenAI follows by making Codex operate in a sandbox and require user confirmation to apply changes to real repositoriesopenai.comopenai.com.
Intellectual property and licensing issues are another major ethical consideration. Codex and Copilot were trained on billions of lines of open-source code, much of it under licenses like GPL, Apache, MIT, etc. This raised the question: Is the AI effectively regurgitating copyrighted code without attribution? In principle, the model learns patterns and doesn’t explicitly copy large chunks verbatim except in rare cases. GitHub released data indicating that exact matches of long code snippets (≥150 characters) from the training set occurred in only about 1% of Copilot’s suggestionsdev.todev.to. That suggests outright plagiarism by the AI is rare. Nonetheless, even 1% at Copilot’s scale means many instances across users. There was enough concern that GitHub introduced a “duplication detection” filter: users can enable a setting that blocks suggestions if they match code from any public repository above a certain lengthresources.github.comnews.ycombinator.com. Essentially Copilot will check its outputs against a database of known code (about 150 characters around the suggestion) and if it finds a match, it suppresses that suggestionnews.ycombinator.com. This helps avoid the scenario where Copilot might output, say, a famous implementation of a function from an open-source project verbatim. By default this filter may be off, but enterprises often turn it on to be safemedium.com.
The legal situation came to a head with a class-action lawsuit in late 2022, where a group of developers alleged that GitHub Copilot’s use of their GPL-licensed code violated copyright. That case (known as the Copilot Intellectual Property Litigation) went through some twists – in 2023 a U.S. court dismissed the majority of claims, including the claim that Copilot infringed copyright, largely because plaintiffs could not show specific instances of Copilot reproducing their code exactlytheregister.comendava.com. The court’s stance, as of mid-2024, was that most outputs of Copilot aren’t verbatim copies and thus don’t violate copyright, and even if small snippets are similar, it might be considered fair use (an analogy drawn was how search engines or Google Books quote text without it being infringement)dev.to. Only a couple of claims, like ones related to insufficient removal of license notices, were left to be litigatedsaverilawfirm.comendava.com. While the legal process is ongoing, the direction seems to favor the idea that AI-generated code is a transformative work, not a simple copy. However, ethical use still dictates caution: GitHub’s own guidance is that developers are responsible for checking the licensing of any code suggestions and including attribution if necessarydev.to. They note that if Copilot does output a substantial snippet from an identified source, the onus is on the user to decide if they can use it under that open-source licensedev.to. In practice, cases of direct copying usually involve boilerplate or very common code (e.g. standard algorithms or templates that might not be protectable by copyright anyway).
From a compliance and privacy standpoint, both OpenAI and competitors have made commitments to protect user data. As mentioned, enterprise users’ code is not fed back into the model for training or fine-tuningopenai.comtechcommunity.microsoft.com. This is crucial for companies worried that their proprietary code could somehow leak out through the AI. OpenAI’s terms for the API and ChatGPT Enterprise guarantee that prompts and outputs are confidential and retained only for a short period (30 days by default on the API, for abuse monitoring) unless the customer opts in to data sharingopenai.comopenai.com. Microsoft’s Azure OpenAI service, which many enterprises use to access Codex/GPT, similarly promises that customer code stays within the tenant and isn’t used to improve the base modeltechcommunity.microsoft.comlinkedin.com. Anthropic likely offers similar assurances for Claude, especially for its commercial clients (Anthropic has been working with some companies under NDA to provide Claude’s services). Ensuring compliance with industry standards, OpenAI completed a SOC 2 audit for its enterprise offerings (verifying security controls)openai.com, and supports features like data encryption in transit and at restopenai.com. These measures are important for sectors like finance or healthcare that have regulatory requirements.
Another ethical aspect is the impact on developers and jobs – while not a “security” issue, it’s a societal consideration. Tools like Codex raise the question of whether they will displace programmers or deskill the workforce. The prevalent view in 2025, supported by surveys, is that most developers do not see AI as a threat to their jobs; rather, about 70% are favorably inclined to use AI as part of their toolkitdevelopers.slashdot.org. Many consider that these tools handle the mundane 20-30% of coding, allowing developers to focus on the creative and complex parts. That said, there is an ethical imperative to ensure developers are not misled by AI outputs – a poorly implemented AI assistant could cause novice devs to learn incorrect practices or blind them to errors. Both OpenAI and Anthropic have incorporated user feedback loops: if the AI suggests something incorrect and the user fixes it, ideally that feedback (if opted in) is used to retrain and avoid such mistakes in future. Over time, this should reduce the frequency of egregious errors. Microsoft and OpenAI also emphasize developer education alongside Copilot: they encourage users to think of Copilot as a junior developer or a helper that still needs oversight. The marketing explicitly calls it “AI pair programmer” – implying you pair with it, not fully delegate.
In summary, the ethics of AI coding tools revolve around balancing tremendous productivity benefits with necessary safeguards. Security-wise, one must treat AI outputs with the same scrutiny as one would treat a human junior developer’s output – review for bugs, test for vulnerabilities, and enforce secure coding practices. The AI can actually help in this regard too: interestingly, you can ask Codex/ChatGPT to review its own code for security issues, and it will often point out potential problems. Some developers use a workflow where Copilot writes code and then ChatGPT (with a security prompt) audits that code. Such human-in-the-loop processes can mitigate risks. Ethically, ensuring attribution for significant code snippets and respecting open-source licenses are important; tooling like Copilot’s filter and user education help address that. The industry is learning and adapting, and there’s ongoing research (and likely future regulations) on how AI and copyright interact. Both OpenAI and Anthropic appear committed to deploying these tools responsibly – they release system cards, allow user control of data, and iterate on safety measuresanthropic.comopenai.com. As AI coding agents become more autonomous, expect even more emphasis on safety – including possibly built-in code linters or security analyzers that automatically flag issues in AI-suggested code. This could become a standard part of AI assistant tools in the near future, effectively merging AI coding with AI code review in one package.
5. Future Roadmap and Challenges
The landscape of AI coding assistants in 2025 is dynamic, and OpenAI’s Codex (along with GitHub Copilot) has a clear roadmap aimed at pushing the boundaries of what these tools can do. One major direction is deepening the integration of Codex into the developer workflow at every stage of the software lifecycle. GitHub’s Copilot X announcements give a glimpse of this future: beyond just code completion, Copilot is being extended to pull requests, documentation, and the command linegithub.bloggithub.blog. In practical terms, this means we’ll see features like:
- AI-assisted Pull Requests: Copilot will not only generate PR descriptions (which it already does in previewgithub.blog), but also guide the PR process. GitHub is testing capabilities where Copilot can suggest additional changes while a PR is open, perhaps identify areas in the code that lack tests, and even warn developers of insufficient test coverage in a PRgithub.blog. The roadmap hints at Copilot automatically suggesting test cases if your PR doesn’t have enough, which developers can accept or tweakgithub.blog. This effectively brings AI into the code review and quality assurance loop, acting as an assistant reviewer.
- Documentation Q&A (Copilot for Docs): GitHub is launching an AI Doc Answering feature, where Copilot can answer questions about your project’s documentation or even the codebase itselfgithub.blog. This uses OpenAI’s models to read through README files, wikis, or even discussions in the repo and provide answers. It’s like having a smart project wiki that you can query in natural language (“How do I use this API in our code?” or “What changed in the last release?”) and get an immediate, context-aware answer. This feature is powered by the latest GPT-4 model and demonstrates how AI can serve as a knowledge agent within software teamsgithub.blog.
- Copilot CLI: There are plans to refine the Copilot CLI experience. Microsoft has shown demos of Copilot in the terminal, where you can describe a shell command in English and the AI will provide the exact command or even execute it with confirmationyoutube.com. For example, “find all JSON files larger than 1 MB and compress them” might yield a correct
find | xargs tarcommand. This expands Codex’s help to DevOps and build tasks, not just writing code. It’s likely we’ll see more of this in tools like Windows Terminal, VS Code’s integrated terminal, etc. - Voice and Multi-modal Inputs: Copilot Voice, which was previewed, allows speaking to the AI to generate codegithub.blog. While in 2023 it was a demo, by 2025 it could become more widely available. This could be a game-changer for accessibility – allowing coding by voice – and for scenarios where a developer’s hands are occupied or when they quickly want to jot down an idea in natural language. Additionally, OpenAI’s models (and possibly future Codex versions) are trending multi-modal. We might envision a scenario where you can, say, upload a screenshot of an error or a diagram, and the AI can incorporate that into its coding process (for example, “here’s a crash log screenshot, help me debug it”).
OpenAI’s future model improvements will also directly benefit Codex. The mention of GPT-4.5 and GPT-5 in OpenAI’s research indexopenai.com suggests that more powerful general models are on the horizon. Codex-1 is based on o3, which is analogous to GPT-4-level reasoning with RL enhancements. We can expect Codex-2 in the future, possibly based on GPT-5 or an advanced version of the o-series, which would further improve capabilities like understanding even more context, handling ambiguous instructions better, and writing more complex programs. One area of focus is likely increasing factual accuracy and reasoning in code. Models still sometimes make logical errors (e.g., off-by-one mistakes, inefficient algorithms) – a more advanced model could reduce those, and maybe even start to handle tasks that require algorithmic innovation. OpenAI might also integrate formal verification or symbolic reasoning into the coding agent to catch logical bugs (there’s research on combining neural nets with symbolic logic for code).
On the challenges side, one big limitation for Codex and similar models has been performing truly deep reasoning or algorithmic creativity. While Codex can solve typical programming tasks, it might struggle with problems that require, say, inventing a new complex algorithm from scratch or proving a mathematical property. This is where DeepMind’s approach with AlphaEvolve shows an alternate path – combining search techniques with AI. OpenAI may need to incorporate similar ideas (like an internal search or self-play mechanism for code quality, which they partially do via RL and test execution). The current Codex agent already does some automated testing and iteration, but scaling that up (so that the AI can, for instance, simulate many different approaches and pick the best) is a challenge due to computational cost. It’s a frontier to make AI not just write code, but also optimize and prove code correctness for complex tasks.
Another limitation is domain expertise in specialized or niche areas. Codex is very strong in mainstream programming languages and common frameworks (JavaScript, Python, React, etc., which dominate its training data). However, in more niche domains – e.g., legacy languages like COBOL, or highly specialized embedded system code, or novel programming languages – it might falter. As of 2025, if you ask Codex to write code in a less common language or for a highly specialized platform, it may produce incorrect or generic outputs simply because it hasn’t seen enough examples. Addressing this could involve fine-tuning Codex on domain-specific data. We might see specialized variants (maybe OpenAI or others release models fine-tuned for, say, data science notebooks, or for front-end web development specifically, etc.). There’s also the prospect of community fine-tuning or customization: OpenAI could allow enterprises to further train Codex on their proprietary codebase so it becomes an expert in their stack (ensuring, for example, it knows their internal APIs). This is not widely available yet, but OpenAI’s platform is moving toward supporting fine-tuning even large models on domain data (they already allow fine-tuning for some GPT-3.5 models; extending that to code models could happen).
One challenge that is actively being worked on is improving the AI’s awareness of its own limitations and uncertainties. Presently, Codex might sometimes output code that it’s not fully “sure” about, and unless tests fail, a user might take it as correct. Future versions could be better at expressing uncertainty – e.g., “I’m not entirely confident in this approach, it might have edge-case bugs” – or even proactively suggesting, “perhaps we should write additional tests for this scenario.” Anthropic’s research into the model’s “thought process” and OpenAI’s system messages both aim to have the AI reason more transparently. If the AI can internally recognize a shaky solution, it could either attempt an alternative or alert the user. This remains hard, but would greatly increase trust if achieved.
On OpenAI’s roadmap, there is also a theme of agents working together. In the Codex introduction, they recommended “assigning well-scoped tasks to multiple agents simultaneously”openai.com. This hints at a future where you might have not just one Codex agent, but a team of AI agents collaborating (for example, one might generate code while another reviews it, and a third writes tests). Such multi-agent setups could mirror a real dev team’s dynamics, potentially catching each other’s mistakes. The challenge is orchestrating these agents – ensuring they communicate effectively and don’t collectively drift into errors. This is active research (some in the AI community are exploring “Societies of AI” or “AutoGPT”-like multi-agent systems for coding). By 2025, we see early signs, but robust multi-agent coding systems are likely a bit further out.
OpenAI’s planned enhancements for GitHub Copilot itself (as gleaned from Copilot X plans and GitHub’s roadmap) include making it more personalized to individual users. GitHub mentioned working to “personalize GitHub Copilot for every team, project, and repository”github.blog. This could mean Copilot will adapt to the patterns in code repos more over time (for example, if your project uses a specific idiom or prefers a certain library for a task, Copilot might learn that and adjust its suggestions accordingly). It might also integrate knowledge of issue trackers and project management – imagine Copilot knowing the context of an open issue you’re working on, so its suggestions are aware of the user story or bug description. In the Copilot X announcement, they hinted at integration with Microsoft’s internal “knowledge model”, which could bring in information from other sources (like documentation, Q&As from Stack Overflow, etc.) directly when providing code suggestionsgithub.blog. Essentially, the AI would not operate in isolation but leverage a network of data relevant to the developer’s task.
Looking a bit further, a key challenge and opportunity is AI autonomy vs. developer control. Right now, Codex and others operate under a paradigm of propose, then the human disposes (i.e., the AI proposes changes, human reviews and approves). As these models get more capable, there will be pressure to automate more – perhaps have the AI automatically merge trivial changes or run routine maintenance tasks on codebases overnight without human intervention. OpenAI’s Codex is still in “research preview” precisely because this kind of autonomy is being tested carefullyopenai.com. The challenge is ensuring safety in those fully autonomous operations. Near-term, the likely approach is progressive autonomy: maybe the AI can automatically open a pull request with changes, but it can’t merge it – a human or at least a separate AI gatekeeper must approve. Or the AI can handle updates that pass all tests and conform to a spec, while anything ambiguous is left for humans. Building trust to get to higher autonomy is a challenge that encompasses technical reliability, extensive validation (e.g., through unit tests, static analysis), and cultural acceptance by developers.
In terms of planned enhancements from competitors (to understand challenges for Codex as well), Anthropic will continue to improve Claude’s coding capabilities – their focus might be on enabling Claude to handle even larger contexts (Claude already handles 100K token context, which is huge) and more tool use. DeepMind/Google’s work with AlphaDev and AlphaEvolve indicates they will try to integrate those breakthroughs into more general tools (Google might, for instance, offer an “AI optimizer” that you can point at a piece of code to have it automatically improve its performance). If OpenAI wants Codex to remain ahead, it might need to incorporate similar optimization strategies – possibly a future Codex could not just write the first-pass solution but then refine it for efficiency, maybe by doing profiling and then refactoring (one can imagine an AI noticing “this code is a bottleneck, let me try a different approach that is 2x faster”).
In summary, the roadmap for Codex and Copilot is about ubiquity and intelligence: putting AI assistance in every corner of development (from coding to code review to devops), and continuously making that AI smarter and more reliable. The current limitations – reasoning errors, handling of niche domains, maintaining context over huge projects, and ensuring security/compliance – are all actively being addressed through larger models, integration of tools (like testing frameworks), and new UX designs. We can expect within a couple of years that an AI like Codex will be capable of taking a natural language feature request (“I need a mobile app that does X”) and delivering a substantial, working draft of the solution, complete with tests and documentation – essentially covering the whole software development cycle. Some pieces of that exist today in isolation; the challenge is to stitch them together robustly. OpenAI’s Codex is arguably the closest to this vision with its current agent approach, and the ongoing enhancements (especially with GPT-4 and beyond powering it) indicate that the gap between what a solo developer can do and what a developer+AI can do will continue to widen in favor of the latter. The ultimate challenge will be ensuring that as these AIs take on more coding responsibilities, they do so in a way that augments human developers and maintains quality – a challenge OpenAI and its peers are keenly aware of, and seemingly committed to solving as part of their future roadmapanthropic.comanthropic.com.
Conclusion: Strengths, Weaknesses, and Best-Fit Use Cases
In conclusion, OpenAI’s Codex (and GitHub Copilot built on it) stands in 2025 as a transformative technology in software development, with clear strengths as well as areas of weakness that users should keep in mind. On the strength side, Codex delivers unparalleled productivity gains for a wide range of coding tasks: it can generate code for common patterns almost instantaneously, perform tedious boilerplate writing (like setting up API clients, writing simple CRUD functions, etc.), and even handle complex tasks like multi-file refactors or debugging with surprising competencyopenai.comanthropic.com. It brings the knowledge of millions of code repositories to your fingertips – making it excellent for reference and learning (e.g., showing how to use an unfamiliar library or API in context). Its integration into GitHub Copilot means it’s available right in the developer’s environment, providing help without interrupting the workflow. The technical prowess of Codex-1 (with the o3 architecture) gives it a huge context window and strong reasoning abilities, which translate to handling big projects and understanding nuanced requests better than earlier generation modelsopenai.comopenai.com. Another strength is Codex’s alignment with human coding practices: thanks to fine-tuning on real pull requests and reinforcement learning from human feedback, its suggestions often feel natural and adherent to best practices out-of-the-boxopenai.com. This reduces the effort needed to clean up AI-generated code. Additionally, OpenAI and GitHub have built an ecosystem around Codex – from the CLI tool for power users to various extensions like Copilot Labs – making it a well-supported platform. Copilot for Business offers enterprise-friendly features (like privacy guarantees and admin controls), which is a strength for organizational adoptionopenai.com. And not to be overlooked, Codex’s multi-language support is broad: it’s proficient not just in Python or JavaScript, but also TypeScript, Go, C#, Java, PHP, Ruby, and even less common languages to a degree (the training data was vast). This makes it suitable for polyglot environments.
The weaknesses and limitations of Codex largely revolve around reliability and scope. While Codex can generate correct solutions for many problems, it is still prone to making mistakes – whether syntax errors (rare, but happen when the prompt is tricky), logical errors, or omissions of important details (like missing a corner case). It lacks true understanding of intent; it pattern-matches based on the data it’s seen, so if you’re doing something very novel or combining concepts in a new way, the AI might get confused or default to the closest known pattern, which could be wrong. For instance, Codex might overly simplify a problem or assume a requirement that wasn’t stated, because it “thinks” it recognizes the task as something familiar. Another weakness is that Codex cannot truly design system architecture or make higher-level decisions – it’s great at implementing, say, a function or a class given a description, but if you ask for a full program, it might not structure it optimally beyond what it has seen in examples. In other words, it’s not going to replace a senior software architect in deciding how to break down a complex project (at least not yet). There are also issues of trust and verification: a recurring theme is that developers must double-check Codex’s output. That overhead means Codex is less helpful in domains where absolute correctness is required and verifying is as much work as writing (e.g., security-critical code where every line must be inspected anyway). Performance-wise, using Codex via the cloud (as Copilot does) introduces latency – usually a couple seconds per suggestion, which is generally fine, but in very large files or very big projects, context handling might slow down or occasionally the AI might miss relevant context due to window limits (even 192k tokens is finite and in practice might not cover an entire huge codebase simultaneously). Cost is a consideration too: while individual developers find Copilot’s subscription worth it, enterprise use of Codex (via API) can incur significant compute costs for very large code or heavy usage, which means scaling it to massive projects needs planning (OpenAI’s pricing for codex models, e.g. codex-mini, is non-trivial for millions of tokens of contextopenai.comopenai.com). Ethically, as discussed, there’s the weakness that it might introduce licensing complications or insecure code if used naively, which one has to be mindful of.
Considering best-fit use cases, Codex shines in scenarios where speed and convenience are valued over absolute precision on the first try. Interactive coding is the primary use case – as you write code, Codex is best at suggesting the next few lines or a helper function, etc. This is fantastic for boosting daily productivity: writing tests, stubs, boilerplate, data transformation scripts, etc., where even if a suggestion isn’t perfect, it gives a huge head start. It’s also excellent for exploratory programming: if you’re not sure how to approach something, you can literally ask (in Copilot Chat or ChatGPT Codex mode) “How might I do X?” and get a starting point. For instance, integrating with a new API – Codex can often provide example code using that API correctly, saving you from digging through documentation. Codex is also very useful for code review assistance: a developer can paste a piece of code and ask Codex “Find bugs or suggest improvements,” and it will highlight potential problems or refactor opportunities. In education and onboarding, Codex is a great fit – new developers can use it to learn by example or to understand legacy code by asking questions about it. In fact, using Codex as a tutor (e.g., “explain what this code is doing”) is a valuable use case, leveraging the model’s ability to generate human-like explanations.
Another ideal use case is test generation and bug reproduction. Given a piece of functionality, Codex can draft unit tests for various scenarios, which is something many developers find tedious. It can also help reproduce a bug if you describe the issue and context. For maintenance tasks like migrating code (say, updating a codebase to a new library version or syntax), Codex can do a lot of the mechanical work: you can prompt it file by file to make the needed changes. Codex’s ability to handle multiple languages means it’s also useful in polyglot projects – e.g., write an algorithm in Python and then ask Codex to translate it to Java, and it will do a fair job, handling the different idioms.
Where is Codex not the best fit (i.e., use cases to be cautious)? One area is extremely critical systems (medical, aviation, crypto protocols) where the cost of a mistake is so high that every line must be verified formally – here, Codex might still assist in writing code faster, but the verification overhead and risk mean you might use it only for non-critical parts. Also, for creative algorithm design or highly novel research code, Codex might not be the best fit – a human expert would likely be needed to devise a truly novel solution, though Codex could help explore the space of possibilities (it might give you a few naive approaches to start from). If the problem is well-defined but complex (like competitive programming problems), Codex can often solve it, but if it’s an open-ended research problem, an AI without additional problem-solving framework will struggle.
In the competitive landscape, Codex remains a top choice for most developers thanks to its integration and balanced performance. Anthropic’s Claude may be the choice for those who need the extra edge in complex reasoning or prefer its flexible CLI approach – for example, a developer dealing with a huge codebase might try Claude if Copilot times out or doesn’t handle the complexity, since Claude’s 100k context and careful reasoning could manage better. Google’s offerings might appeal to those already in Google’s ecosystem or needing on-prem solutions (Google has hinted at on-prem or self-hosted versions of their models for cloud customers). But overall, Codex (via Copilot) is often the default recommendation, with its strength in generalist support across many tasks, solid reliability from continuous improvement, and the backing of the GitHub platform which most developers use daily.
To wrap up, OpenAI’s Codex as of 2025 has demonstrated remarkable strengths: it increases developer productivity and happiness, offers extensive capabilities from code generation to automated testing, and integrates smoothly into development workflows. Its weaknesses – occasional errors, need for oversight, and some ethical concerns – are important to understand, but with proper practices they are manageable. The best-fit use cases are those that play to Codex’s strengths: use it as an accelerant and assistant in the loop, not as a fully autonomous coder (not just yet). In that role, it’s like a force multiplier for developers, handling the repetitive and boilerplate so developers can focus on creativity, critical thinking, and complex problem-solving. Teams that leverage Codex (Copilot) effectively have reported significant time savings and even the ability to tackle more ambitious projects with the same resourcesopenai.comwindowscentral.com. As the technology continues to mature – with fiercer competition from Anthropic, Google, and others – developers stand to gain an even more powerful ally. The future where AI pair programmers are standard is quickly becoming reality, and OpenAI’s Codex is leading the charge in transforming how software is written, reviewed, and maintained for the better.
Sources:
- OpenAI, “Introducing Codex.” (2025) – OpenAI blog announcing Codex agent featuresopenai.comopenai.comopenai.com.
- OpenAI, “Introducing OpenAI o3 and o4-mini.” (2024) – Research release on the models underlying Codexopenai.comopenai.com.
- GitHub Blog, “GitHub Copilot X: The AI-powered developer experience.” (2023, updated 2024) – Plans for Copilot’s new features (chat, voice, PRs)github.bloggithub.blog.
- Stack Overflow Blog, “Developers get by with a little help from AI – Code Assistant Survey.” (May 2024) – Survey of 1,700 developers on AI tool usage and feedbackstackoverflow.blogstackoverflow.blog.
- APIpie.ai, “Top 5 AI Coding Models of March 2025.” – Benchmark comparison of Claude, OpenAI o-series, etc., on coding tasksapipie.aiapipie.ai.
- Anthropic, “Claude 3.7 and Claude Code Announcement.” (2025) – Describes Claude 3.7’s performance and the introduction of Claude Codeanthropic.comanthropic.com.
- The Register, “Google DeepMind debuts AlphaEvolve coding agent.” (May 15, 2025) – News on AlphaEvolve’s algorithm discoveriestheregister.comtheregister.com.
- Dev.to, “Avoiding accidental open-source laundering with Copilot.” (Jul 2022) – Discussion of Copilot’s licensing issues and 1% code match statisticdev.todev.to.
- Pearce et al., “Asleep at the Keyboard? Assessing the Security of GitHub Copilot’s Code Contributions.” (2021) – Academic study finding ~40% of Copilot outputs had vulnerabilitiesarxiv.orgcyber.nyu.edu.
- Thoughtworks Blog, “Claude Code experiment – saved 97% work then failed.” (Mar 2025) – Case study of using Claude Code, highlighting strengths and pitfallsthoughtworks.comthoughtworks.com.
- GitHub Blog, “The economic impact of AI-powered developer tools.” (Jun 2023) – Research by GitHub on Copilot’s productivity impact (30% code written by AI, 55% faster task completion)github.bloggithub.blog.
- Windows Central, “Over 15 million developers now use GitHub Copilot.” (May 1, 2025) – Article citing Microsoft’s report of Copilot user growthwindowscentral.com.
- OpenAI, “Enterprise privacy at OpenAI.” (Oct 2024) – OpenAI’s policy on not training on customer dataopenai.comopenai.com.
- Stack Overflow Survey 2024 – (Image) Primary code assistant usage among developers【36†】.
- Anthropic – (Image) Claude vs OpenAI vs others on SWE-Bench accuracy【34†】.